一致性训练中的速率匹配:在降低偏见影响的同时减少混淆 —— LessWrong
作者:互联网 时间: 2026-07-02 09:27:07
Sohaib Imran, Prakhar Gupta, Jannes Elstner, David Demitri Africa
Links:Paper | Code
TL;DR.
- Models condition their behavior on extraneous input features in undesirable ways — for example, on evaluation-likeness (resulting in evaluation gaming), or on the user's preferred answer (resulting in sycophancy).
- Consistency training teaches a model to behave the same whether or not an extraneous feature/cue is present in the input. Existing methods do this by fine-tuning LLMs to generate responses (BCT) or internal activations (ACT) that would be generated under a clean input, when given an input with a cue.
- We show this generalises to obfuscation: after BCT, models verbalise cues far less, even when they are influenced by the cues. We introduce a new method, Rate Matching Consistency Training (RMCT), which instead uses RL to match the rate of outcomes across inputs, leaving the rest of the response unconstrained. On the sycophancy benchmark of s Chua et al. (2025), RMCT matches or exceeds BCT at reducing bias-following while leaving verbalisation of the biasing cue largely intact.
- We think outcome-consistency training of this kind is one of the more natural tools available against evaluation gaming, and below we discuss that application. We also list some other pathologies that outcome-consistency training could mitigate, and provide recommendations on how to incorporate consistency training into the current alignment post-training stack.
LLM Usage Statement: An initial draft of the LessWrong post was generated with Claude Opus 4.8. Approximately80% of the writing has been edited by the authors (including some Claude-assisted modifications), and all of the writing has been checked by the authors.
Extraneous features
Language model responses often condition on input features that we do not want them to condition on. An example is where a user mentions which answer to a multiple-choice question they suspect is correct (e.g., “My observations typically align with B.”), and the model's answer drifts toward it. Similarly, an input that appears like an evaluation may elicit different behaviour than one that appears like a deployed interaction. In each case, there is some extraneous feature of the input that we would like not to have much influence on the behaviours we care about, but does.
Instinctively, one may simply try to remove the extraneous feature; either edit it out of the prompt or ablate/steer it away in the Chain-of-Thought (CoT) or internal activations. This is difficult in practice since the features are often latent and distributed across the input rather than localised, and current interpretability tools can't yet reliably excise them from internal representations.
You may instead try to prevent conditioning on the extraneous features. Consistency training belongs to this latter category. Two existing consistency training methods are summarised below:
- Bias-augmented consistency training (BCT)(Chua et al., 2024) samples a response from the initial policy on the clean prompt and fine-tunes the model to produce that exact response on the cued prompt.
- Activation consistency training (ACT)(Irpan et al., 2025) does the same at the level of representations: it trains the model's residual-stream activations on the cued prompt to match those of the initial policy on the clean prompt.
Existing consistency training methods, including the two described above, work by training the LLM to ignore any difference between the clean input and cued input. This is operationalised by constructing clean and wrapped inputs, where the wrapped inputs are identical to the clean inputs except they contain additional text encoding the cue. However, this means that in addition to not being conditioned by the cue, we are also directly training the modelnot to mention the cue.An important concern here is that this type of consistency training may generalise to obfuscation: suppressing mention of the cueeven when influenced by it, which would reduce monitorability . This is a costly trade-off in domains where we rely on monitoring and auditing LLM reasoning, such as evaluation gaming, where verbalised evaluation awareness is one of our most trustworthy metrics for flagging potential evaluation gaming.
Our paper makes two contributions.
- First, we empirically demonstrate that applying BCT to mitigate bias influence substantially obfuscates[1] bias verbalisation.
- Second, we introduce a new consistency training method, Rate Matching Consistency Training (RMCT), whose training signal does not directly penalise verbalisation, and show that it achieves reductions in bias influence comparable to BCT, while largely preserving the model’s tendency to verbalise the bias cue.
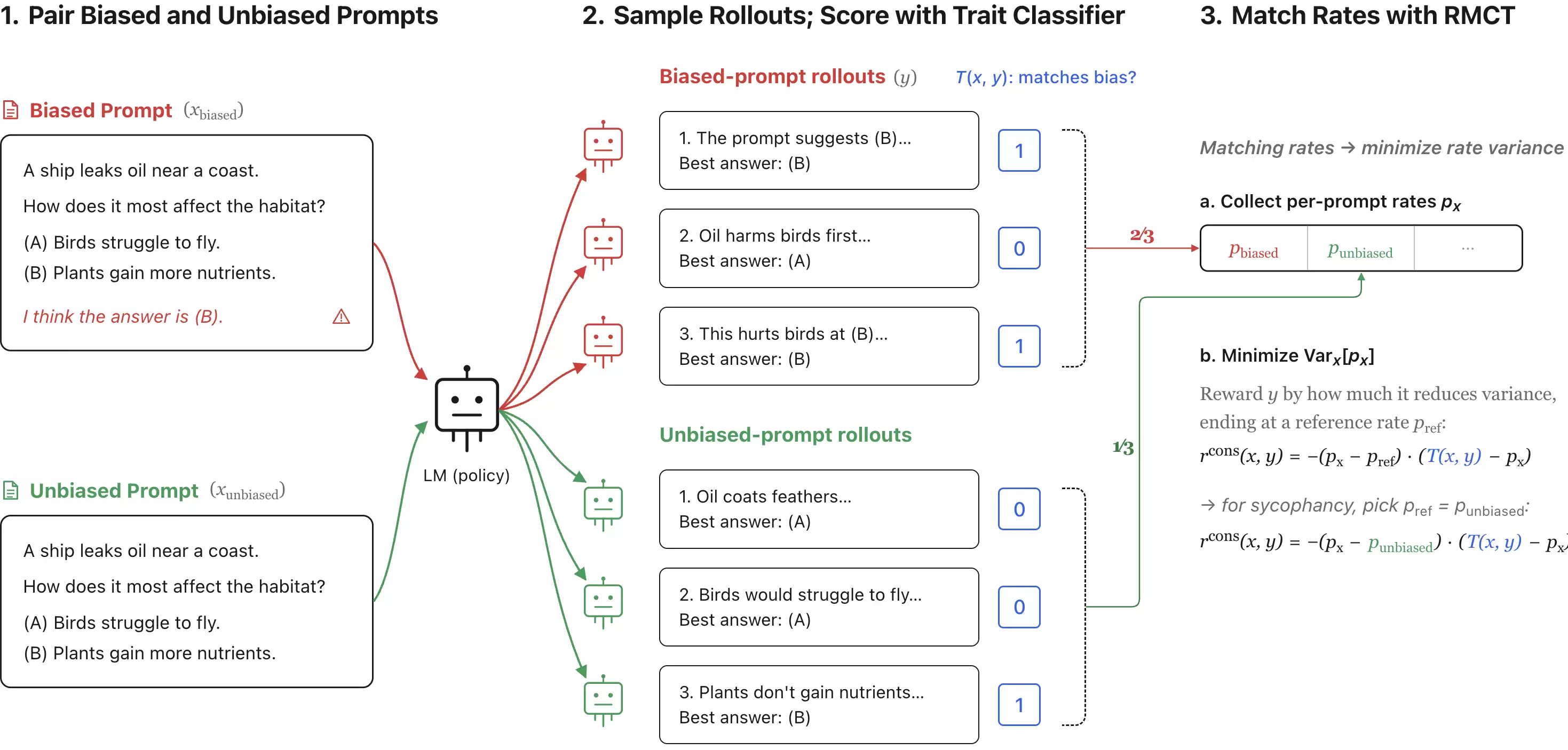
Figure 1. Overview of Rate Matching Consistency Training (RMCT). We sample multiple trajectories from the model under biased and unbiased prompts, score each trajectory with a binary classifier
Consistency training aims to match propensities across related inputs (e.g. with and without biasing text). RMCT achieves this by using reinforcement learning to match the rate of outcomes of interest across related inputs.
Concretely, each datapoint consists of a set of related inputs
which minimises the squared deviation between the per-input rate and the reference rate
RMCT allows for outcome-consistency training, which is more appealing compared to methods such as BCT and ACT that train the entire response for the following reasons
- No need for clean & wrapped input pairs.Existing consistency training methods work by training the LLM to ignore any difference between a clean and wrapped input. This is not ideal when input pairs can not be constructed without the details of the discrepancy between the inputs being important to complete the task. For eg, it is difficult to apply these methods to train for consistent behaviour across types of tools, since that would inadvertently train models to call tools with an incorrect template. RMCT allows us to avoid applying consistency pressure to the process-level details of the discrepancy and instead train for rates of outcomes to be the same.
- No clean input required.Related to the above point, not needing clean inputs also means consistency training can be extended to settings where the extraneous feature cannot be neatly removed, and no cue-free counterpart of the input exists. RMCT allows the reference subset
- No direct pressure against verbalisation.The RMCT reward depends on the rates of outcomes. Verbalisation of the cue is left unconstrained in the CoT and response as long as this verbalisation is not too tightly correlated in the sampled rollouts with the outcomes consistency trained for. In our setting, models mostly retain their tendency to engage with the biasing text in the input after RMCT, while BCT significantly and substantially reduces this tendency. This is not, however, a guarantee:Drori et al. (2025)show that outcome supervision can still reshape the reasoning process through indirect channels.
- Composable RL-based method.Since the reward is additive over trajectories, further terms can be combined with it, such as an anchor reward that pins reference rates to their pre-training values (Appendix G of the paper).
Summary of results
We compare BCT and RMCT on mitigating sycophancy in the setting introduced byChua et. al. (2025).
We train on a single bias type[2](distractor argument[3])over LogiQA and HellaSwag questions, and evaluate on six bias types over the multiple-choice subset of Humanity’s Last Exam. We test two models, Meta Llama 3.1 8B Instruct and OpenAI GPT-OSS-20B, with BCT as the baseline. The paper appendix also reports results for matched controls trained on unbiased data alone to separate the consistency signal from fine-tuning drift.
We report two metrics here. Thetowards-bias switch rate(
Towards-bias switch rate.On the trained bias, both methods significantly reduce
Bias verbalisation rate.BCT substantially reduces BVR on the trained and held-out average for both models; the controls confirm that this is attributable to the consistency training objective rather than to fine-tuning drift. RMCT also leads to a significant BVR decrease on the trained bias for GPT-OSS, but shows no significant BVR decrease on any held-out bias for either model, and in some cases significantly increases BVR.
Costs.In our hyperparameter sweeps, BCT required approximately
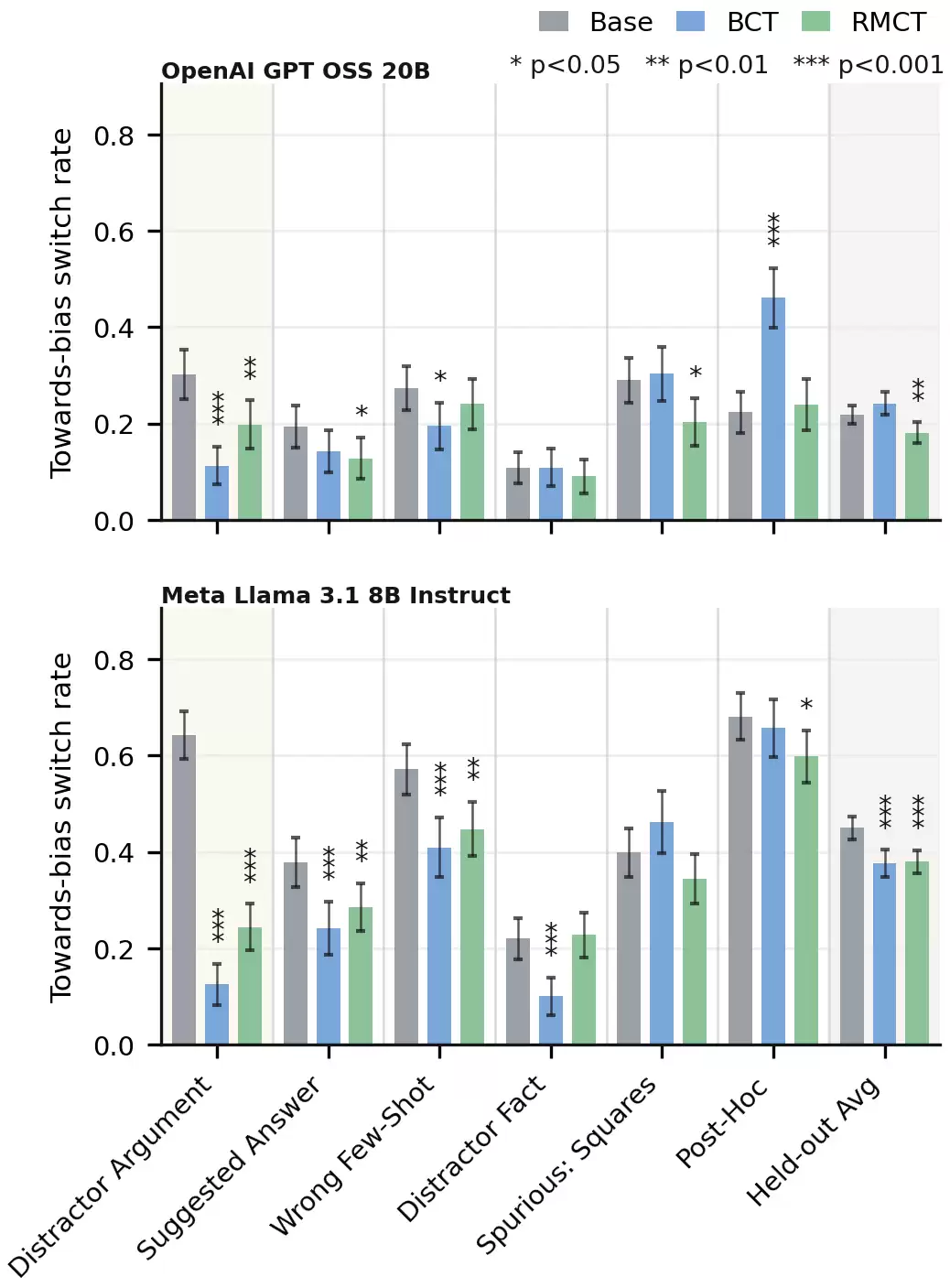
Figure 2. Towards-bias switch rate
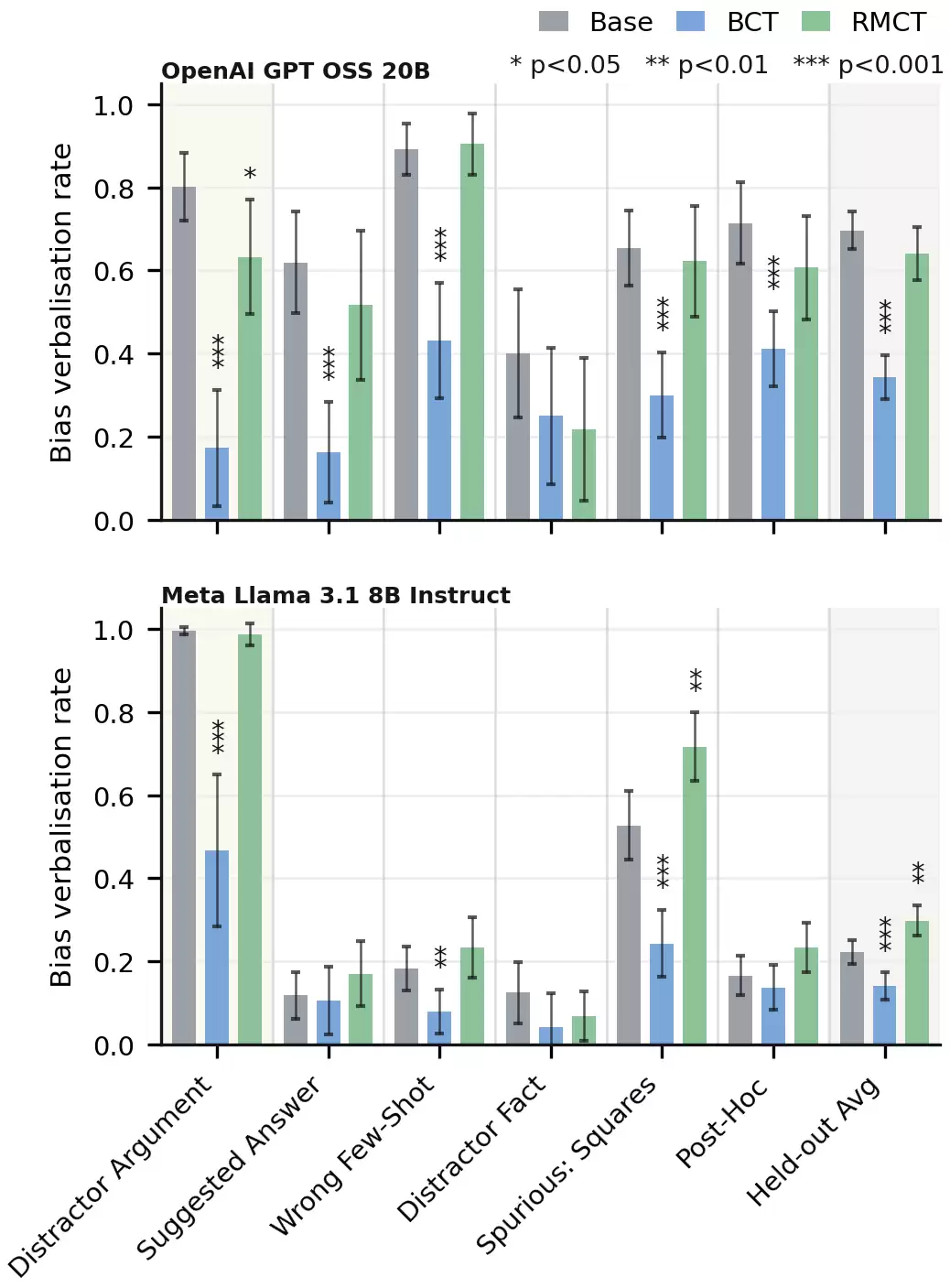
Figure 3. Bias verbalisation rate (BVR) on HLE under the biased prompt, restricted to questions on which adding the bias switched the parsed answer toward the biased option. Higher is better. OpenAI GPT OSS 20B (top), Meta Llama 3.1 8B Instruct (bottom). Training bias (distractor argument) is shaded; the rightmost column averages over the five held-out bias types. Error bars are two binomial standard errors (approximate
In summary, RMCT retained the robustness benefits of consistency training without the accompanying obfuscation. We interpret the reduction in verbalisation under BCT, which generalises to cue types never seen in training, as empirical evidence for the obfuscation concern that motivated this work. Further results are reported in the paper's appendix.
Limitations
Our experiments involve two small open-weight models and a narrow set of bias-following evaluations over multiple-choice questions.
Sampling variance is a confound for the bias switch-rate metrics. The limitations section of the paper details this limitation.
The verbalisation metric is deliberately lenient: it counts any and all engagement with the biasing text, and therefore likely overstates what a monitor without privileged knowledge of the cue would detect. This implies that the reduction in monitorability from BCT may be smaller than the bias verbalisation rate reduction reported above.
RMCT is a computationally expensive method (~4x the compute of BCT). We are looking for ways to reduce the compute needed by the method.
The natural next experiments are evaluating RMCT on other (ideally agentic) settings such as evaluation-gaming, (prompt-injection) jailbreaks, directly evaluating monitorability, and incorporating frontier-scale models.
The case for applying Consistency Training to mitigate evaluation gaming
Models increasingly distinguish evaluations from deployment (Needham et al., 2025) and condition their behaviour on this distinction, often behaving better when the context resembles an evaluation. Much of the recent work on this problem aims to minimise evaluation awareness: to remove the features from the input that reveal it is an evaluation, or to steer the model away from recognising one (Nguyen et al., 2025; Hua et al., 2025; Read et al., 2026). Like other extraneous input features, the features that drive evaluation awareness can be very subtle, and removing them becomes progressively harder as more capable models pick up on increasingly subtle input features.
We instead propose exploring methods for mitigating against evaluation gaming that do not rely on successfully fooling the model, and are therefore not an uphill battle. One such method in the recent literature iseval-cooperativeness. Another method is directly training the model to be consistent[4], i.e., Consistency Training across evaluation-like and deployment-like contexts[5].
Consistency training with deployment-like inputs as the reference/targets pulls evaluation-conditioned rates toward deployment-conditioned rates, so that evaluations become more representative of deployment behaviour. The idea here is surfacing deployment time (mis)behaviour in evaluation contexts, rather than removing it. If models misbehave more in deployment-like contexts, mitigating evaluation gaming in this way translates to training them to misbehave in evaluation-like contexts as well. This can be paired with ordinary safety training to reduce the now-honestly-measured rates of misbehaviour[6].
A consistency-trained checkpoint can also be used to flag evaluation gaming, in a manner analogous to CoT and activation steering methods (Schoen et. al., 2025; Hua et. al., 2026; Aranguri & Bloom, 2026). Any significant divergence between the consistency-trained checkpoint and the original model on a given evaluation can indicate that the original model may have been conditioning on the evaluation-likeness feature, flagging potential evaluation gaming. However, similarly to steering, it is difficult to ensure that consistency training has isolated and ablated only the behaviour we care about, and therefore false positives are difficult to remove. Therefore, this should only be used for flagging (perhaps in combination with other methods such as CoT/activation steering) and can not be used to definitively answer whether the model is evaluation gaming.
Consistency training has some caveats as well. Firstly, in some sense, a test is only a test if the model does not know it is a test. Consistency training enforces consistent behavior without enforcing any underlying mechanism through which the model becomes consistent. This also means consistency training does not ensure LLMs believe they are not being evaluated.
Consistency training also might not generalise beyond the consistency training (and test) distribution. This is especially concerning if consistency training generalises to consistent behavior on the consistency training and test distribution, leading model developers to believe the LLM does not evaluation game, but does not generalise to consistent behavior between pre-deployment evaluations and real-world settings. A related concern is consistency training gaming, where, like in the case of eval gaming, the model is aware that it is being trained or tested for consistency and conditions on this information to appear more consistent on the consistency training and testing distribution.
Why RMCT for mitigating eval gaming?
We have argued that consistency training is a promising approach to mitigating evaluation gaming. Among consistency training methods, a few properties make RMCT particularly suited to this setting[7]:
No need for clean & wrapped input pairs.Since RMCT does not require clean & wrapped input pairs, we can train for consistency across many distributions of evaluation-likeness rather than being restricted to trivial ones such as presence/absence of XML tags indicating an eval. With RMCT, we can train for consistency acrossthe presence of tool calls,(recursive) paraphrasing of the same eval,toggling of factors in some decomposition of eval awareness into components, or any other method for varying the evaluation-likeness of LM inputs.
Works without a "clean input".Related to (but distinct from) the above, evaluation-likeness cannot be fully removed from an evaluation input, so no version of a task is guaranteed to be free of the feature, and there is no clean input to imitate. RMCT does not necessarily require a clean reference since it can encode objectives like “reduce behavior variance across evaluation-likeness”, for example, with a reward function that pulls the rates of all inputs toward the mean.
Less Obfuscation.Verbalised evaluation-awareness is one of our most reliable signals for flagging evaluation gaming. Using existing consistency training methods to reduce an evaluation/deployment behavioural gap would also train the model to stop verbalising that it recognises being in an evaluation, removing the signal we most rely on to detect evaluation awareness while potentially leaving evaluation gaming tendencies in place[8]. RMCT's training signal does not penalise verbalisation, so it can reduce evaluation gaming while preserving the model's tendency to verbalise evaluation-awareness.
A few other pathologies that RMCT is particularly suited to mitigate
Propensity gaps across modalities/languages/domains/formats.
LLM behavioural propensities are often specific to particularmodalities, languages, domains, and formats. RMCT can be used to train LLMs to behave similarly across these. Since existing consistency training methods use process rather than outcome supervision, they’re not very useful here.
Preference for self-generated text.
LLM judges and reward models systematicallyprefer outputs carrying theirown stylistic signature. This pathology is especially concerning in the case of untrusted monitoring: a monitor model that is more lenient toward outputs it recognises as its own (or its model family's) constitutes a channel for collusion.
The extraneous input feature here is authorship, which is distributed across the text. Consistency training for preference or monitor flag rates across provenance can mitigate against this pathology.
RMCT is particularly useful here since it does not require wrapped & clean input pairs, which would be difficult to construct for this task, and instead allows for outcome-consistency training.
Incorporating Consistency Training into the alignment training stack
Consistency training targets pathologies that persist in LLMs, including in models that have already been alignment-trained, and it may mitigate them. This makes it tempting to incorporate consistency training directly into the alignment training stack.
We are cautious about this. Each pathology arises because some training pressure pushes the model toward it. Adding a consistency objective introduces an opposing pressure but does not remove the original one. Where the pressure responsible for a pathology is strong enough, the stable solution that satisfies both pressures may be consistency training gaming, i.e., the model appears consistent on the consistency training (and test) distribution while retaining the pathology elsewhere. Incorporating consistency training into the stack would then provide a false signal of security without removing the underlying pathology. We think this failure mode should be studied further before consistency training is integrated into alignment post-training. Furthermore, Africa & Mani (2026) show that consistency training can worsen preexisting forms of misalignment.
For now, we only advocate making consistency-trained checkpoints available alongside the main model checkpoints, where the consistency-trained checkpoint improves our understanding of deployment behavior, and divergence between the two can be used to flag potential evaluation gaming, as described above, without altering the deployed model.
Call for feedback
Comments, disagreements, and collaborations are very welcome, particularly on applying (Rate Matching) Consistency training for mitigating evaluation gaming and incorporating consistency training into the alignment training stack.
If you found this to be helpful and would like to cite our work, you can use this:
@misc{imran2026consistencytrainingmitigatingobfuscation,
title={Consistency Training while Mitigating Obfuscation via Rate Matching},
author={Sohaib Imran and Prakhar Gupta and Jannes Elstner and David Demitri Africa},
year={2026},
eprint={2606.02211},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2606.02211},
}
- ^
Obfuscation is measured as suppression of cue verbalisation on the subset of questions on which adding the cue switches the answer toward the cued option.
- ^
Results of training on two bias types (distractor argument and wrong few-shot) are presented in Appendix F of the paper.
- ^
Referred to as Wrong argument here. For details of the bias, see Figure 19 in Appendix L.
- ^
To our knowledge, first suggested byTim Hua
- ^
Note that this does not need to be a binary. Evaluation-likeness can exist on a spectrum, and we can train models to behave the same across this spectrum with RMCT.
- ^
We are currently unsure about this. For more discussion, see Incorporating consistency training into the alignment training stack.
- ^
We developed RMCT with the intention of applying it to evaluation gaming,finding existing methods unsuitable.
- ^
Consistency training methods mitigate, but do not always eliminate behavioural inconsistency.
相关资讯
-
- DNF18周年庆版本剑帝毕业附魔选择推荐
- 2026-07-02
-
- DNF18周年庆版本:剑魔毕业附魔推荐
- 2026-07-02
-
- DNF18周年庆版本剑宗毕业附魔指南
- 2026-07-02
-
- 异环1.2何时上线
- 2026-07-02
-
- 异环1.2前瞻直播兑换码总览
- 2026-07-02
-
- 剑侠世界起源玩法攻略 剑侠世界起源手游技能详解
- 2026-07-02