Agent Skills 开发指南:6 字段规范、3 级加载、5 步评估闭环:一套通用方法论跑通从零到上线
作者:互联网 时间: 2026-07-02 09:54:06
 Agent Skills 开发指南信息图封面
Agent Skills 开发指南信息图封面
图 1:Agent Skills 开发指南信息图封面 - 6 字段规范、3 级加载、5 步评估闭环
你在用 AI agent 干活时,多半撞过这堵墙:模型本身很强,但一碰到你的真实业务就掉链子。
它不知道你公司的 API 怎么鉴权,不知道你那套 CSV 报表要按哪个列做聚合,也不知道某个第三方 SDK 在 v3 之后有个反向兼容的坑。
把 prompt 塞满?换一个项目就全废了。写一个 system prompt 模板?换一个 client 又得重粘一遍。
Agent Skills 想解决的就是这件事。
它既不是框架,也不是 SaaS,而是一个轻量、开放的格式规范 - 把过程性知识和项目特有的 context 打包成一个文件夹。任何兼容的 client 都能发现、披露、按需激活。
这篇文章把官方文档站(agentskills.io)和参考实现仓库 skills-ref 的源码通读了一遍,整理成一份开发指南,覆盖格式规范、开发实战、评估迭代三块。所有数字、字段、约束都来自 specification.mdx 和 skills-ref 源码,文档没写的特性这里也不会出现。
1. Skills 到底是什么:一句话定位
先把概念说清楚,免得和别的名词混淆。
Agent Skills 是一种文件夹格式:一个目录,里面放一份 SKILL.md(必需)加上任意可选的 scripts/、references/、assets/。SKILL.md 用 YAML frontmatter 描述元数据,用 Markdown 写指令。
它解决的核心问题是 README 里那句话:agent 越来越强,但做真实工作时缺少必要 context。Skills 不去增强模型能力,而是把这三类东西打包成可移植、可版本化、按需加载的资产:
领域专长:法律评审、数据分析流水线、演示文稿格式等专门知识可复现工作流:把多步任务变成一致、可审计的流程跨产品复用:一次构建,任意兼容 client 都能用仓库许可证是 Apache 2.0(代码)/ CC-BY-4.0(文档),由 Anthropic 发起,现在作为开放标准维护。
需要划清的边界:仓库不收录社区 skill 目录(CONTRIBUTING.md 明确说明),只维护格式规范和参考实现。skills-ref 这个 Python 参考库源码里也写明了仅供演示,非生产用途。
2. 渐进式披露:整个设计的灵魂
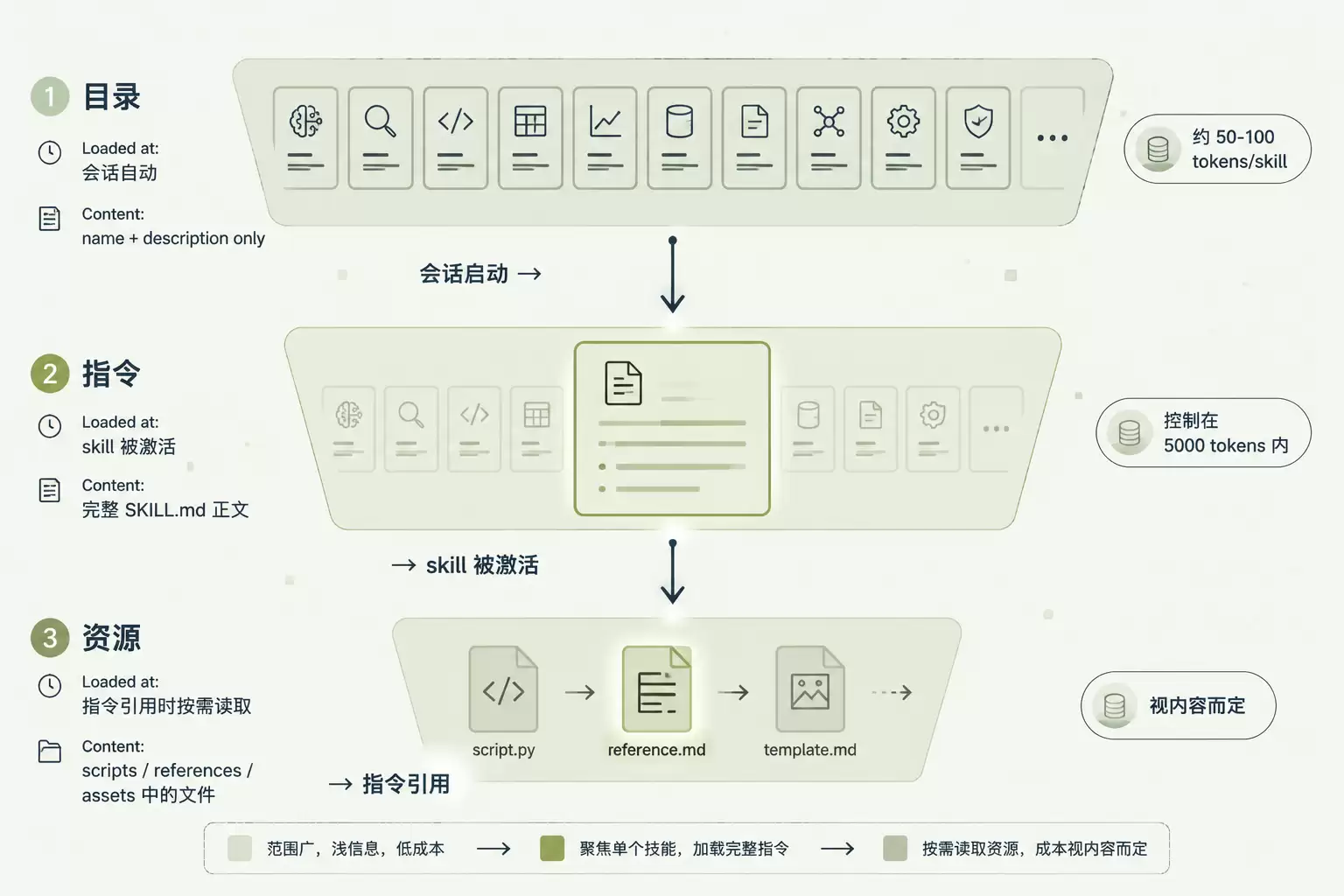
理解 Skills 的关键不是记住字段名,而是理解渐进式披露(Progressive Disclosure)这个三阶段模型。后面所有的约束、最佳实践、运行时行为,都是从这里推导出来的。
 渐进式披露三阶段示意图
渐进式披露三阶段示意图
图 2:渐进式披露三阶段 - Catalog → Instructions → Resources 的加载时机和 token 成本递增
层级 | 加载内容 | 时机 | Token 成本 |
|---|---|---|---|
| Catalog 目录 | name description | 会话启动时 | 约 50-100 tokens/skill |
| Instructions 指令 | 完整 SKILL.md 正文 | skill 被激活时 | 推荐控制在 5000 tokens 内 |
| Resources 资源 | scripts/references/assets 中的文件 | 指令引用时按需读取 | 视内容而定 |
这个分层带来的直接后果是:装 20 个 skill 不会预付 20 套指令的 token。会话启动时,agent 只看到所有 skill 的 name description 加起来约一两千 token;只有被激活的那个,才会把完整 SKILL.md 读进 context;只有指令里点名要读的 references 文件,才会真的去打开。
这反过来给开发者定了三条硬规矩:
description 独自承担触发责任(第一层只看它)SKILL.md 正文要克制(一旦激活整篇进 context,建议 500 行 / 5000 token 以内)大段资料移到外部文件(按需引用,而不是全塞进 SKILL.md)记住这三条,后面所有为什么这么写都能对上号。
3. 格式规范:从目录到字段的全约束
目录结构
一个 skill 长这样:
代码语言:markdown复制skill-name/├── SKILL.md# 必需:元数据 指令├── scripts/# 可选:可执行代码├── references/ # 可选:参考文档├── assets/ # 可选:模板、资源└── ... # 任意额外文件/目录
SKILL.md 必须叫这个名字(skills-ref 的 find_skill_md 优先匹配大写,也接受小写 skill.md)。其他目录是约定,不是强制。
SKILL.md 的组成
YAML frontmatter Markdown 正文。frontmatter 用 --- 包裹,闭合 --- 之后 trim 出来的就是正文。
---name: pdf-processingdescription: >Extracts text and tables from PDF files, fills PDF forms, andmerges multiple PDFs. Use when working with PDF documents orwhen the user mentions PDFs, forms, or document extraction.license: Apache-2.0compatibility: Requires Python 3.10 and the pdfplumber package.metadata:author: someoneversion: "1.0"allowed-tools: Read Write Bash---# PDF Processing这里是指令正文……
Frontmatter 字段约束表
下面这张表是 specification.mdx 原表的整理,每个数字都在 skills-ref/src/skills_ref/validator.py 里有对应常量:
字段 | 必需 | 约束 |
|---|---|---|
| 是 | 最长 64 字符;只能小写字母/数字/连字符;不能以连字符开头或结尾;不能连续连字符;必须与父目录名一致 |
| 是 | 最长 1024 字符,非空。描述 skill 做什么、何时使用 |
| 否 | 许可证名或指向打包的 license 文件 |
| 否 | 最长 500 字符,环境要求说明 |
| 否 | 任意键值对,键名建议加前缀避免冲突 |
| 否 | 空格分隔的预批准工具串(实验性,实现差异可能很大) |
源码里能直接对上的几个常量:MAX_SKILL_NAME_LENGTH = 64、MAX_DESCRIPTION_LENGTH = 1024、MAX_COMPATIBILITY_LENGTH = 500,允许的字段集合是 {"name", "description", "license", "allowed-tools", "metadata", "compatibility"}。
name 校验细节
name 的校验比看上去严:
做 NFKC 归一化不能大写不能首尾连字符不能出现-- 连续连字符字符只能是 isalnum() 或 -必须等于父目录名spec 文档说unicode 小写字母数字,但 skills-ref 的源码用的是 Python 的 c.isalnum(),实际允许 unicode 字母(这是 i18n 的友好实现)。
合法与非法的例子(spec 原文):
✅ 合法:pdf-processing、data-analysis、code-review❌ 非法:PDF-Processing(大写)、-pdf(首连字符)、pdf--processing(连续连字符)description 写法对比
description 是触发 skill 的唯一信号,所以 spec 专门给了好坏对比:
好的 description 同时覆盖做什么和何时触发,差的那种只说和 X 有关,agent 没法判断该不该激活。description 优化的完整方法论放在第 7 节展开。
正文(Body)
正文格式不限。spec 推荐的章节有:分步指令、输入输出示例、常见边界情况。
关键提示 - agent 一旦激活,会把整个 SKILL.md 读进 context。所以主 SKILL.md 建议控制在 500 行内、5000 token 内,详细资料移到独立文件按需引用。
文件引用
用相对路径从 skill 根目录引用:
代码语言:markdown复制See [the reference guide](references/REFERENCE.md) for details.Run: scripts/extract.py
建议引用深度保持一层,别搞深层嵌套链。
用 skills-ref 做验证
官方参考实现 skills-ref 提供三个 CLI 命令,是开发期最常用的工具:
# 校验 frontmatter 合法性和命名约定skills-ref validate ./my-skill# 输出 skill 属性的 JSONskills-ref read-properties ./my-skill# 生成两个 skill 的 <available_skills> XML(给 prompt 用)skills-ref to-prompt ./skill-a ./skill-b
三个命令都支持传 skill 目录或直接传 SKILL.md 文件路径,内部用 _is_skill_md_file 判断后取 parent。
也有 Python API:
代码语言:python复制from pathlib import Pathfrom skills_ref import validate, read_properties, to_prompt# 返回错误列表,空列表 = 合法problems = validate(Path("my-skill"))# 返回 SkillProperties dataclassprops = read_properties(Path("my-skill"))# 生成 <available_skills> XML,注入到 system prompt 用prompt = to_prompt([Path("skill-a"), Path("skill-b")])
注意 to_prompt 会用 html.escape 转义 name/description,location 用 find_skill_md(skill_dir) 解析后的真实路径。
4. 从零开发一个 skill
光讲规范太抽象,走一遍真实工程场景。假设要做这么个 skill:帮 agent 处理我们公司内部的一个 Markdown 文档库,按特定规则生成 API 文档。
第一步:先真实地完成一次任务
best-practices.mdx 反复在讲一件事 - 从真实专长出发,而不是让 LLM 空想。
典型的坑:打开 Claude,让它帮我写一个 API 文档生成的 skill。
得到的结果大概率是一堆模糊的通用流程 - 妥善处理错误、遵循认证最佳实践 - 而不是你公司真正需要的 API 模式、边界情况、项目约定。
正确的姿势是两种之一:
从实操任务提取:自己手动跑一遍真实的文档生成任务,记录奏效的步骤、做的纠正、输入输出格式、提供的项目特有 context从已有项目制品合成:内部文档、runbook、style guide、API 规范、schema、code review 评论、issue 跟踪、版本历史 patch、真实失败案例关键:要的是项目特有材料,不是通用参考文献。
第二步:搭目录结构
代码语言:markdown复制api-doc-generator/├── SKILL.md├── scripts/│ └── validate_links.py├── references/│ ├── api-conventions.md│ └── error-codes.md└── assets/└── endpoint-template.md
第三步:写 frontmatter
代码语言:yaml复制---name: api-doc-generatordescription: >Generate API reference docs from our internal Markdown doc repository.Use this skill when the user wants to produce, update, or audit APIendpoint documentation — including when they paste a raw route handler,share a docs/ path, or mention "API doc" without specifying the format.license: Apache-2.0compatibility: Requires Python 3.10 . Runs validate_links.py with `uv run`.metadata:author: platform-teamsource-version: "2026.06"allowed-tools: Read Write Bash---
description 这里踩了几个点:祈使语气(Use this skill when...)、列具体触发场景、覆盖用户没直接点名关键词的情况("without specifying the format")。这几条都是 optimizing-descriptions.mdx 的原则,第 7 节会展开。
第四步:写正文
正文里塞 high-value 的内容,不塞大路货。best-practices 的判断法很直接:每段内容都问自己一遍 - 没有这条指令,agent 会搞错吗?答不会,删。
代码语言:markdown复制# API Doc Generator## 流程1. 读取目标路由处理器源文件,抽取路由路径、HTTP 方法、参数、返回类型2. 套用 assets/endpoint-template.md 的结构生成初稿3. 跑 `uv run scripts/validate_links.py <生成的文件>`,必须全部通过4. 对照 references/api-conventions.md 检查命名是否符合内部约定## Gotchas- **响应包装层**:所有成功响应都被 `ResponseWrapper` 包了一层 `{code, data, msg}`,文档里必须显示包装后的结构,不是 handler 直接 return 的对象- **deprecated 路由**:仓库里标了 `@deprecated` 的路由**不要**生成新文档,而是在已有文档顶部加一段迁移指引,指向替代路由- **错误码**:handler 抛的异常类对应到 references/error-codes.md 里的标准码,别用异常类的字符串名当 error code## 何时读哪个 reference- 路径参数命名拿不准 → 读 references/api-conventions.md 第 2 节- API 返回非 200 → 读 references/error-codes.md 找对应码
注意几个细节:
流程是显式 checklist,不是散文描述Gotchas 段塞的是项目特有的、违反合理假设的事实,不是记得写注释这种废话何时读哪个 reference 给了精确的条件触发,而不是泛泛的see references/ for details后面会看到,这几个细节分别对应了 best-practices 里高价值指令模式的不同套路。
第五步:跑 validate
代码语言:bash复制skills-ref validate ./api-doc-generator
没有报错就过。这一步只检查 frontmatter 合法性,覆盖不到内容质量 - 内容质量要靠第 8、9 节的评估循环。
5. 最佳实践的核心原则
best-practices.mdx 是整个文档站里密度最高的一篇,把开发期最容易踩的坑都拆开了。这里挑 4 条最核心的讲。
从真实专长出发
这条已经在第 4 节走过一遍,不重复。要点是:项目特有材料而不是通用参考资料。
用真实执行来迭代
初稿几乎都要改。best-practices 的诊断信号很具体 - 读 agent 执行 trace,不只看最终输出。
agent 浪费时间的常见原因有三类:
指令太模糊,要试好几种方法才找对指令对当前任务不适用,但 agent 还是机械执行选项太多没默认值,agent 在选项之间反复横跳每发现一次纠正,就把纠正加进 SKILL.md(通常进 Gotchas 段)。这是 skill 进化的主要方式。
花好 context 预算
skill 一旦激活,整个 SKILL.md 进入 context window,和对话历史、system context、其他激活的 skill 抢注意力。所以加内容不是无脑加,每加一段都要算账。
加 agent 缺的,省 agent 知道的
聚焦 agent 不知道的:项目约定、领域流程、不明显边界、特定工具/API。不需要解释 PDF 是什么、HTTP 怎么工作。
设计连贯单元
像设计函数:一个 skill 封装一个连贯、可组合的工作单元。
太窄 → 一个任务要加载多个 skill,开销 指令冲突太宽 → 难精确激活spec 给的例子:查数据库 格式化结果是一个连贯单元;再加数据库管理就太宽。
中等详细度
过度全面的 skill 反而帮倒忙 - agent 难提取相关部分,可能被不适用的指令带偏。简洁分步 可运行示例胜过详尽文档。
用渐进式披露组织大型 skill
SKILL.md < 500 行 / 5000 token,只放每次都要用的核心指令。详细资料移 references/。
关键细节:告诉 agent 何时加载哪个文件。best-practices 里反复出现的一组对比 -
前者是条件触发,后者是甩锅。
校准控制力
把指令精度匹配到任务脆弱性
场景 | 策略 |
|---|---|
多种方法都行、任务容许变化 | 给 agent 自由,讲清 why 比死板规定有效 |
操作脆弱、一致性重要、必须按特定顺序 | 死板规定,写死步骤 |
给默认,别给菜单
多工具/多方法可行时,挑一个默认 简短提替代。别列等价选项让 agent 选。
偏好流程,而非声明
skill 应教 agent 如何处理一类问题,而不是为某个具体实例产出什么。
具体细节可以有:输出模板、绝不输出 PII 这类约束、工具特定指令。但方法要可泛化。
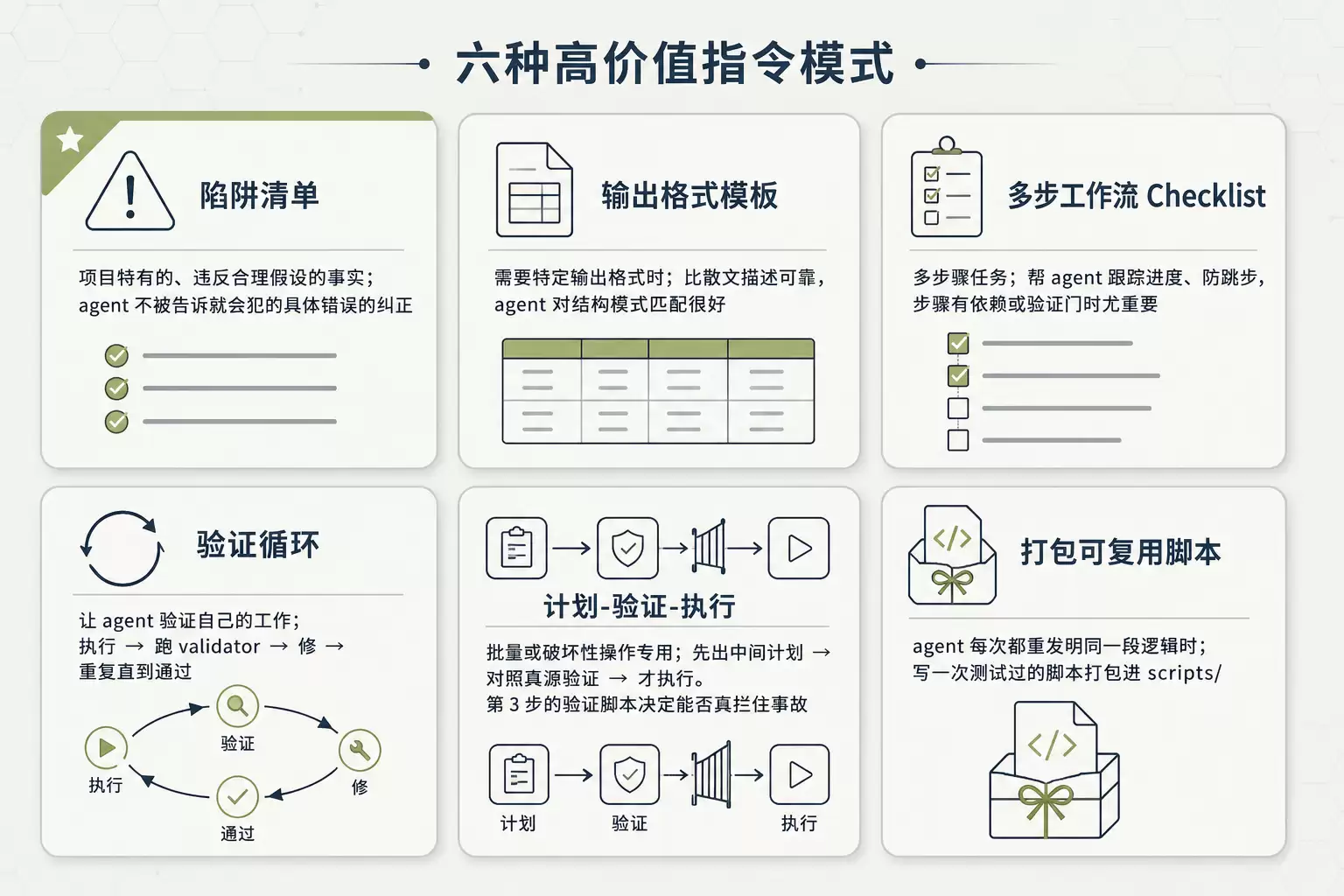
6. 高价值指令模式:六种好用的套路
best-practices.mdx 列了六种高价值指令模式。注意它的提醒 - 不是每个 skill 都要全用,按需挑。
 高价值指令模式速查图
高价值指令模式速查图
图 3:六种高价值指令模式速查 - Gotchas/模板/checklist/验证循环/Plan-Validate-Execute/打包脚本
Gotchas 段(陷阱清单)
不少 skill 里价值最高的就是这一段。它装的是违反合理假设的环境特有事实,不是通用建议 - 是 agent 不被告诉就会犯的具体错误的纠正。
放在 SKILL.md 里,让 agent 在遇到情境前就看到。迭代信号:你纠正 agent 一次,就把纠正加进 gotchas。
代码语言:markdown复制## Gotchas- 这个 API 在凌晨 2-4 点(UTC)有计划维护窗口,会返回 503。重试 3 次仍失败就提示用户改时间- v3 SDK 之后,`getUser(id)` 不再接受数字 ID,必须传字符串。遇到数字 ID 要先 toString()
输出格式模板
需要特定输出格式时给模板,比散文描述可靠 - agent 对具体结构模式匹配很好。
短模板内联在 SKILL.md;长模板或仅特定情形需要的,存 assets/ 按需引用。
以 API endpoint 文档模板为例,结构大致这样:
代码语言:markdown复制### {METHOD} {path}{一句话描述}#### 参数| 名称 | 类型 | 必填 | 说明 ||------|------|------|------|| id | int| 是 | 资源 ID |#### 响应{ "code": 0, "data": {...}, "msg": "ok" }
占位符({METHOD}、{path}、{一句话描述})保留在模板里,agent 套用时直接替换。
多步工作流 checklist
显式 checklist 帮 agent 跟踪进度、防跳步,尤其步骤有依赖或验证门时。第 4 节的 api-doc-generator 示例里就用到了。
验证循环
让 agent 在继续前验证自己的工作:do work → 跑 validator(脚本 / 参考 checklist / 自检)→ 修 → 重复直到通过。
参考文档也可以充当 "validator" - 比如让 agent 对照 references/api-conventions.md 自检。
Plan-Validate-Execute
批量或破坏性操作专用:先让 agent 在结构化格式里出中间计划 → 对照 source of truth 验证 → 才执行。
关键成分是第 3 步:一个对照真源的验证脚本,错误信息要够具体让 agent 自我纠正。这一步决定整个模式是真能拦住事故,还是只是仪式感。
打包可复用脚本
迭代时对比执行 trace,如果发现 agent 每次都独立重发明同一段逻辑(建图、解析特定格式、验证输出)→ 这是信号:写一次测试过的脚本,打包进 scripts/。
7. Description 优化:让 skill 被正确触发
description 是触发 skill 的唯一信号,写得好不好直接决定 skill 会不会被用起来。optimizing-descriptions.mdx 给了一套完整的方法论。
 description 优化循环图
description 优化循环图
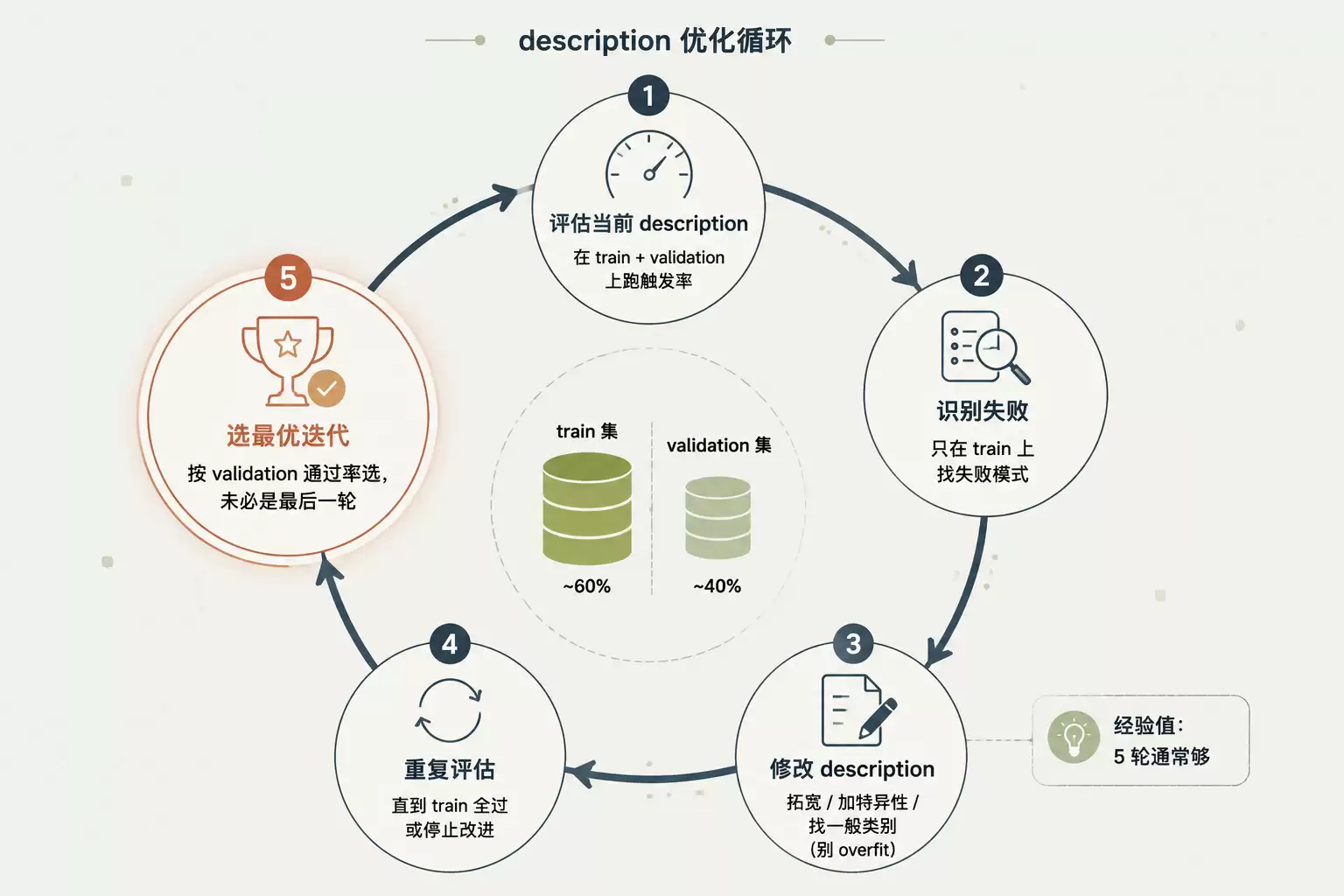
图 4:description 优化循环 - Train/Validation split → 评估 → 识别失败 → 修 description → 再评估
触发机制的真相
会话启动只加载 name description,任务匹配 description 才会读完整 SKILL.md。description 独自承担触发责任。
但有个容易被忽略的细节:agent 通常只对超出它自身能力的任务才查 skill。
读这个 PDF 这种一步任务,可能不会触发 PDF skill,即便 description 完美匹配。涉及陌生 API、领域流程、罕见格式的任务,才是 description 写得好能产生差异的地方。
写好 description 的四条原则
用祈使语气:Use this skill when... 而非 This skill does...。agent 在决定是否行动,告诉它何时行动聚焦用户意图,非实现:描述用户想达成什么,不是 skill 内部机制倾向 "pushy":明确列出适用 context,包括用户没直接点名的情形(even if they don't explicitly mention 'CSV' or 'analysis.')保持简洁:几句到一小段。硬上限 1024 字符触发 eval 设计
光有原则不够,要有可测量的 eval。需要一套 query 集 - 真实用户 prompt,标注是否应触发。约 20 条起步:8-10 条该触发 8-10 条不该触发。
should-trigger 的变化轴:措辞(正式 / 随意 / 有错别字)、显式度(直接点名领域 vs 描述需求不点名)、详细度、复杂度。
最有价值的 should-trigger 是:skill 能帮但单看 query 不明显的。
最有价值的 should-not-trigger 是 near-miss:共享关键词/概念但实际要的不同的。
CSV skill 的强负例对比:
❌ 弱负例:Write a fibonacci function(太明显无关)✅ 强负例:I need to update the formulas in my Excel budget spreadsheet(共享 "spreadsheet" 关键词,但要 Excel 编辑,非 CSV 分析)真实性提示:真实 prompt 含路径、个人 context、具体细节、随意语言、缩写、错别字。别造得太干净。
测试触发的工程做法
每条 query 用 agent 跑,观察是否调用 skill。模型非确定性 → 每条跑多次(3 次是合理起步),算触发率。
阈值用 0.5:
should-trigger 触发率 > 0.5 算过should-not-trigger < 0.5 算过20 query × 3 次 = 60 次调用,必须脚本化,手跑会疯。
防 overfitting:train / validation split
Train 约 60%:用来识别失败、指导改进Validation 约 40%:搁置,只查改进是否泛化两集都按比例混正负例只用 train 的失败指导修改,无论手改还是让 LLM 提议。validation 是最终裁判。
优化循环
按这个顺序走:
在 train validation 上评估当前 description在 train 上识别失败修 description:should-trigger 失败 → 太窄,拓宽范围 / 加 contextshould-not-trigger 假触发 → 太宽,加特异性 / 划清边界别加失败 query 的具体关键词(那是 overfit),找它代表的一般类别几轮卡住 → 试结构性不同思路,而非渐进微调检查不超 1024 字符(优化中容易膨胀)重复 1-3 直到 train 全过或停止改进按 validation 通过率选最优迭代(最优未必是最后一个,早期可能更泛化)经验值:5 轮通常够。anthropics/skills 仓库里的 skill-creator skill 能自动化这个循环。
改造前后对比
optimizing-descriptions.mdx 给的官方示例:
代码语言:yaml复制# Beforedescription: Process CSV files.# Afterdescription: >Analyze CSV and tabular data files — compute summary statistics,add derived columns, generate charts, and clean messy data. Use thisskill when the user has a CSV, TSV, or Excel file and wants toexplore, transform, or visualize the data, even if they don'texplicitly mention "CSV" or "analysis."
改造后覆盖了:做什么(多个具体动作)、何时触发(明确的文件类型 意图)、pushy 表述("even if they don't explicitly mention")。
8. 输出质量评估:用 eval 量化 skill 的价值
description 优化解决是否被激活的问题,这一节解决激活后输出好不好。evaluating-skills.mdx 给了一套完整的质量评估方法论。
测试用例三要素
prompt:真实用户消息expected_output:人类可读的成功描述(不是确切字符串,是描述)input files(可选)存 evals/evals.json。
写好 prompt 的提示:
从 2-3 个起步,别过度投入变化措辞、详细度、正式度覆盖边界(畸形输入、异常请求、指令歧义)用真实 context(路径、列名、个人背景)with / without 对比模式
每个用例跑两次:with skill vs without skill(或旧版本),得基线。
工作区结构(每个完整循环一个 iteration-N/,每个用例有 with_skill/ 和 without_skill/ 子目录,含 outputs/、timing.json、grading.json,汇总到 benchmark.json)。
每轮从干净 context 开始 - 有 subagent 能力的用 subagent(天然隔离),没有就用独立 session。
捕获 timing:记录 token 与时长。skill 大幅提质量但 token 翻倍,和既好又省,是完全不同的权衡,要分开判断。
写 assertion
先看首轮输出再写 assertion - 往往不知道好长什么样,直到看过。
好 assertion 的标准:可程序验证、具体可观察、可计数。
弱 assertion 的两种典型:太模糊(输出是好的)、太脆(要求确切短语)。
非一切都需要 assertion - 风格、视觉、感觉对这种难以分解成 pass/fail,留人工 review。
评分(Grading)
每条 assertion 对实际输出评 PASS/FAIL 具体证据(引用 / 参考输出,不是只说意见)。
最简:把输出 assertion 给 LLM 评。可代码验证的(合法 JSON、行数、文件存在)用脚本 - 机械检查脚本比 LLM 判断更可靠。
两条评分原则:
PASS 必须有具体证据,不给 benefit of the doubt。有 "Summary" 标题但只有一句模糊话 → FAIL(标签在,实质不在)同时复查 assertion 本身:太易(总过)/ 太难(总不过)/ 不可验证 → 都要修盲比较作为补充:两版本输出给 LLM judge 不标来源,自定 rubric 打整体质量分。
benchmark.json 汇总
代码语言:json复制{"run_summary": {"with_skill":{ "pass_rate": {"mean": 0.83, "stddev": 0.06} },"without_skill": { "pass_rate": {"mean": 0.33, "stddev": 0.10} },"delta": { "pass_rate": 0.50, "time_seconds": 13.0, "tokens": 1700 }}}
delta 告诉你 skill 的代价(更多时间/token)和收益(更高 pass rate)。这两条放一起看才完整。
四种分析模式
拿到结果后按这四类排查:
删 / 换两配置都总过的 assertion - 不反映 skill 价值查两配置都总不过的 - assertion 坏 / 用例太难 / 检查错对象重点研究 with 过 without 不过的 - skill 在哪增值、为什么结果跨 run 不一致 → 高 stddev → 可能 eval flaky 或指令歧义,加示例 / 具体指导别忘了查时间/token 异常值,读执行 transcript 找瓶颈。
人工 review
人工捕捉 assertion 没覆盖的问题。每用例存 feedback.json,要具体可执行 - 缺轴标签是好反馈,看起来差是无用反馈。
迭代循环
三个信号源:
失败 assertion(具体缺口)人工反馈(更广质量问题)执行 transcript(why 出错)把三者 当前 SKILL.md 给 LLM 提议修改,原则四条:
从反馈泛化(skill 用于很多 prompt,不只测试用例)保持精简(更少更好的指令常胜过详尽规则)解释 why(reasoning-based > rigid directives)打包重复工作(每次都重发明 → 进scripts/)循环:给信号 SKILL.md → LLM 提议 → 人审应用 → 新 iteration → 评分 → 人审 → 重复。满意 / 反馈持续空 / 停止改进时停。
9. 脚本工程实践:让脚本配得上 agent
skill 里经常会带脚本。using-scripts.mdx 把脚本使用分成了三档:一次性命令、引用 scripts、自包含脚本 - 外加一节专门讲为 agentic 使用设计的硬性要求。
一次性命令:能用现成的就别造
现有包直接做你需要时,在 SKILL.md 直接引用,无需 scripts/。多个生态有运行时自动解析依赖的工具:
工具 | 生态 | 备注 |
|---|---|---|
| Python (uv) | 缓存激进,重复跑近即时;需单独装 |
| Python | 成熟替代;OS 包管理器可用性更广 |
| npm | 随 Node.js;下载运行缓存; |
| Bun | npx 替代;仅 Bun 环境 |
| Deno |
|
| Go | 内置于 go; |
一次性命令的工程提示:
锁版本(npx [email protected])让行为随时间稳定在 SKILL.md 声明前置条件(如 需 Node.js 18 ),运行时级用 compatibility frontmatter复杂命令移进 scripts/,测试过的脚本更可靠引用 scripts
相对路径从 skill 根目录。在 SKILL.md 列出可用 scripts,然后在工作流里指示 agent 运行 - 别让 agent 自己猜有哪些脚本可用。
自包含脚本:内联依赖声明
不想强迫用户预装依赖的话,用自包含脚本,把依赖声明内联进文件本身:
语言 | 内联依赖机制 | 运行 |
|---|---|---|
Python | PEP 723( |
|
Deno |
|
|
Bun | import 路径锁版本,无 node_modules 时自动装 |
|
Ruby |
|
|
Python 的 PEP 723 长这样:
代码语言:python复制# /// script# requires-python = ">=3.10"# dependencies = [# "requests>=2.31",# "rich>=13",# ]# ///import requestsfrom rich import print# 脚本正文……
用 uv run script.py 跑,uv 会按 # /// 块声明临时建环境、装依赖、执行,零配置。
为 agentic 使用设计脚本:硬性要求
这一节是 using-scripts.mdx 里最值钱的部分。agent 读 stdout/stderr 决定下一步,脚本的设计选择直接决定它是否好被 agent 用。
避免交互式提示(硬性要求)
agent 在非交互 shell 运行,无法应答 TTY、密码、确认。脚本里出现交互提示会无限挂起。所有输入走 flag / env / stdin。
代码语言:bash复制# ❌ 坏:脚本挂起等输入environment = input("Select environment: ")# ✅ 好:缺失就给具体错误# Error: --env is required. Options: development, staging, production.# Usage: deploy.py --env ENV [--dry-run]
用 --help 记录用法
agent 了解脚本接口的主要方式就是 --help。它要含:简述、flags、示例。保持简洁 - 输出会进 context。
写有用错误信息
agent 收到错误,信息直接塑造下一次尝试。不透明的 Error: invalid input 浪费一轮。
好错误信息要说三件事:出了什么错、期望什么、该试什么。
用结构化输出
偏好 JSON / CSV / TSV 而非自由文本。可被 agent 和标准工具(jq/cut/awk)消费,便于管道组合。
数据与诊断分离:结构化数据 → stdout;进度 / 警告 / 诊断 → stderr。这样 agent 解析 stdout 拿干净数据,需要调试时再看 stderr。
其他几条
幂等性:agent 可能重试,create if not exists 比 create and fail on duplicate 安全输入约束:用 enum / 闭集拒歧义输入dry-run 支持:破坏性操作给 --dry-run有意义的退出码:不同失败类型不同码,记进 --help安全默认:破坏性操作要显式确认 flag可预测输出大小:许多 harness 会自动截断超阈值(10-30K 字符)的工具输出。大输出默认给摘要 / 合理上限,支持 --offset 翻页;或要求 --output flag 指定文件 / - 显式 opt-in stdout10. 运行时怎么工作:开发者需要知道的部分
完整客户端实现指南在 adding-skills-support.mdx,那篇是给想给自家 agent 加 skills 支持的团队看的。作为 skill 开发者,不需要全部细节,但有几个点会影响你怎么写 skill,单独拿出来说一下。
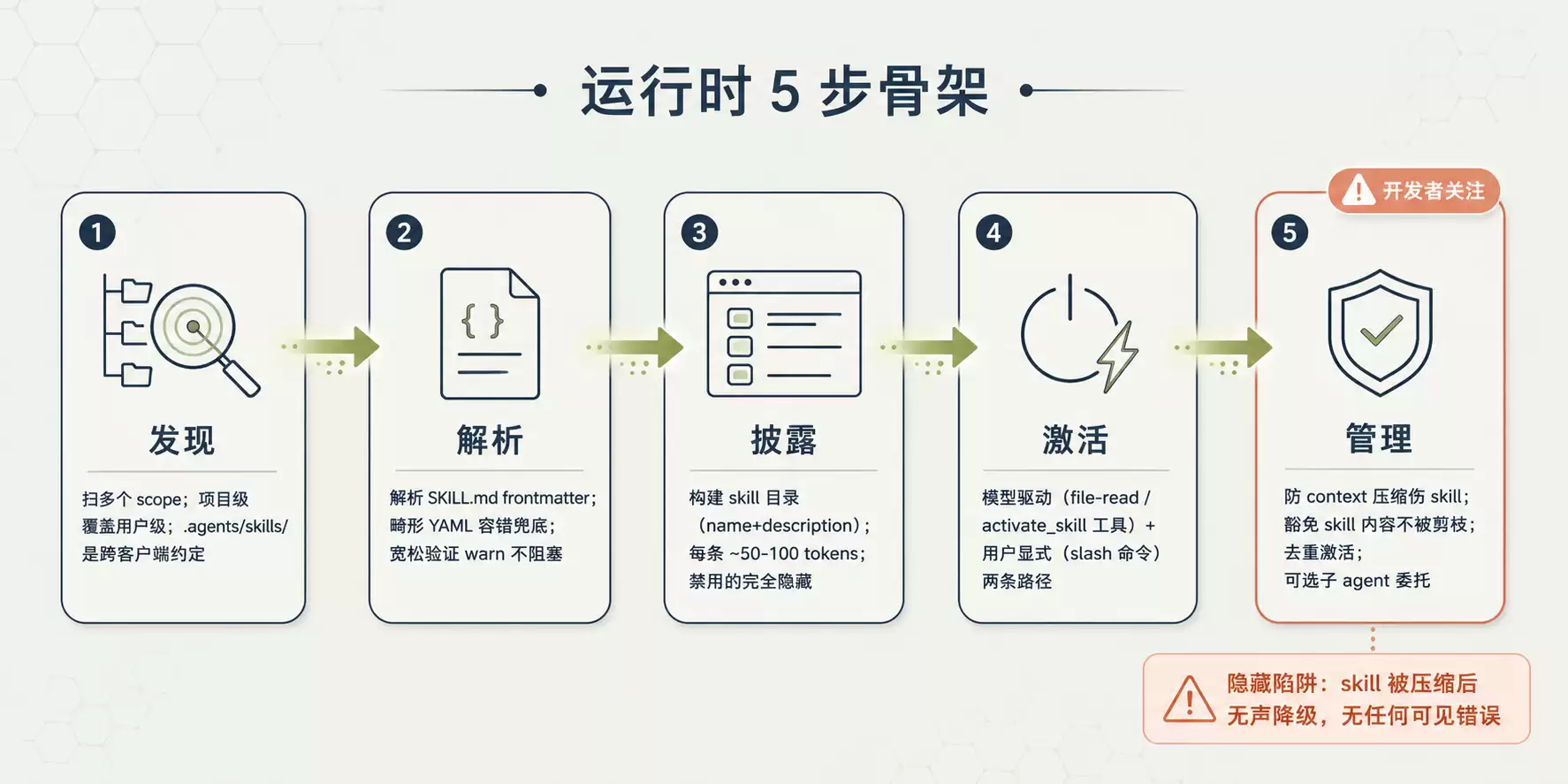 运行时 5 步骨架图
运行时 5 步骨架图
图 5:运行时 5 步骨架 - 发现 → 解析 → 披露 → 激活 → 管理
运行时分 5 步骨架:发现(Discovery)→ 解析(Parsing)→ 披露(Disclosure)→ 激活(Activation)→ 管理(Management)。
发现:skills 放在哪里
客户端扫多个 scope(project 级、user 级,可选 org 级、内置)。每个 scope 内扫客户端专属目录 .agents/skills/ 跨客户端约定:
Scope | 路径 |
|---|---|
Project |
|
User |
|
.agents/skills/ 是跨客户端共享的事实约定 - spec 不规定 skill 目录在哪,只规定里面装什么。
部分实现也扫 .claude/skills/(项目级 用户级)以兼容现有 skill。其他可能的位置:祖先目录到 git root(monorepo 用)、XDG、用户配置路径。
命名冲突的通用约定:项目级覆盖用户级。所以同一个 name,project 里的版本会赢过 user 里的版本。
信任考量:项目级 skill 来自当前仓库,可能不可信(刚 clone 的开源项目)。有些客户端会设信任门 - 只加载用户标记可信的项目级 skill。
解析:畸形 YAML 的容错
客户端解析 SKILL.md 时,常见的畸形是未加引号值含冒号。规范的做法是兜底:包引号或转 YAML block scalar 后重试。
宽松验证策略:警告但不阻塞加载 -
name 不匹配目录名 → warn 加载name 超 64 → warn 加载description 缺 / 空 → 跳过(披露必需)YAML 完全不可解析 → 跳过所以你的 skill 即使有小毛病也能跑,但别指望靠这个偷懒 - 不同客户端容错程度不一样。
披露:catalog 是什么样子
客户端构建 skill 目录(name description 可选 location),结构化格式皆可。skills-ref 的 to_prompt 输出长这样:
<available_skills><skill><name>pdf-processing</name><description>...</description><location>/home/user/.agents/skills/pdf-processing/SKILL.md</location></skill></available_skills>
每 skill 约 50-100 token。这就解释了第 2 节那张表里会话启动约 50-100 tokens/skill是怎么来的。
过滤行为:用户禁用 / 权限拒绝 / disable-model-invocation flag 的 skill 会从目录完全隐藏,而不是列出后在激活时阻塞。
无 skill 时:省略目录和行为指令,别显空 <available_skills/> - 会迷惑模型。
激活:两条路径
模型驱动激活(主流):多数实现靠模型自身判断,不做 harness 侧关键词匹配。两种模式:
File-read 激活:模型用标准文件读工具读 catalog 给的 SKILL.md 路径。最简,模型有文件访问即可专用工具激活:注册activate_skill 工具,吃 skill 名返回内容。模型不能直接读文件时必需,能读时也有用 - 可以控制返回内容(剥 / 留 frontmatter)、用结构化标签包内容、列 bundled 资源、强制权限、跟踪激活供分析用户显式激活:用户应能直接激活 skill,不等模型决定。最常见形式是 slash 命令或 mention 语法(/skill-name、$skill-name),harness 拦截、查表、注入。
管理:context 压缩是个隐藏陷阱
这一步对开发者最重要的一点是 - 防 context 压缩伤 skill。
agent 截断 / 摘要旧消息时,应该豁免 skill 内容。skill 指令是持久行为指导,会话中途丢失会无声降级 - 模型继续操作但没了专门指令,无任何可见错误。
常见做法:把 skill 工具输出标 protected 让剪枝算法跳过;用结构化标签识别并在压缩时保留。
这就解释了为什么 SKILL.md 要克制 - 越长越容易在边缘 case 被压缩算法误伤。
其他两条管理要点:
去重激活:跟踪当前会话已激活的 skill,重复激活时跳过重注入子 agent 委托(高级,部分客户端支持):skill 不注入主对话,而在独立子 agent 会话跑,子 agent 收指令、执行、返回摘要。适合 workflow 复杂到值得专一会话的 skill11. 把开发、评估、迭代串起来
回头看一下,一个成熟 skill 的生命周期其实是三个嵌套的循环:
触发循环(description)
代码语言:markdown复制设计 description → 跑触发 eval(20 query × 3 次)→ 用 train 失败指导修改 → 用 validation 选最优迭代
质量循环(SKILL.md 正文 scripts)
代码语言:markdown复制跑 with/without eval → 失败 assertion 人工反馈 执行 transcript→ 给 LLM 提议修改 → 人审应用 → 新 iteration → 评分
实战循环(真实任务)
代码语言:markdown复制对真实任务跑 → 读执行 trace → 纠正 → 加进 gotchas 或调整流程
三个循环不是线性的,会相互喂信号。
比如 description 触发率上不去,可能是正文太长被压缩;质量循环里某条 assertion 总不过,可能是流程缺一步;实战里反复纠正同一类错误,那就是 gotchas 该补条目了。
把这三个循环跑顺,skill 才会越用越准。
总结
最后给几条写作时反复用到的判断标准,做个收尾:
关于格式 - 记住三个数字:64 / 1024 / 500(name / description / compatibility 的字符上限),以及 SKILL.md 的 500 行 / 5000 token 软上限。这些数字背后都是渐进式披露的 token 经济学。
关于内容 - 每段都问一遍没有这条 agent 会搞错吗。从真实专长出发,不从 LLM 空想出发。Gotchas 段几乎总是高价值区。
关于评估 - 没有 eval 的 skill 是盲盒。description 用触发率 eval,正文用 with/without 对比 eval,真实任务用执行 trace。三套信号缺一不可。
关于生态 - Agent Skills 的 spec 还在演进,CONTRIBUTING.md 写明的原则是:加东西易、删东西难;每个新特性都给所有实现者增加复杂度;存疑时宁缺勿滥。所以读官方文档永远是第一手资料 - 这篇文章里的所有数字和约束,都建议对照 agentskills.io 上的 specification.mdx 复核一遍,特别是当你看到本文的日期(2026-06-30)之后又有更新时。
写 skill 这件事,本质上是把你脑子里那些没法言传的隐性经验,一条条翻译成 agent 能照着执行的显性指令。工具链现成、规范开放,剩下的就是反复打磨了。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
相关资讯
-
- 今古群侠传:赵公公相关任务剧情分享
- 2026-07-02
-
- 火柴人大战免费在线入口 火柴人大战小游戏免费版
- 2026-07-02
-
- 火柴人大战在线地址 火柴人大战小游戏免费在线入口
- 2026-07-02
-
- 《万物皆可蟹:动物进化》你展现速度成就解锁全攻略
- 2026-07-02
-
- 崩坏因缘精灵夜影好用吗
- 2026-07-02
-
- 《红色沙漠》欧德克守护者套装获取攻略 如何获得被遗忘的将军同款装备
- 2026-07-02