graphify 与 claude 图谱关系
作者:互联网 时间: 2026-07-03 08:25:06
Graphify 将代码库转化为知识图谱,助你快速理清项目结构与核心逻辑。核心内容:1. Graphify工具与Claude的集成使用方法2. 使用Go语言sync.map包进行效果验证3. Graphify构建知识图谱的过程与输出结果
Graphify 是一个开源的知识图谱构建工具,将知识库转换为知识图谱,来帮助AI 更好地理解项目结构。我会想,这个东西的作用究竟有多大?至少它并没有在我的工作域流行起来。
按照仓库 README 我们先安装 graphify,建议我们先安装 uv 工具,它是下一代 Python 工具链,旨在替代传统的 pip。uv 是使用 rust 开发的,是用新的语言实现了一遍旧的功能吗?
uv tool install graphifyy这里安装的是 graphifyy,最后是双y,主要是 graphify 单词已经被占用了。如果名称被抢占的话,开源项目有一套常见的命名策略,这可能也算是其中的一种。
现在我们将 graphify 注册到 claude 中,在 claude 通过技能来使用它。这里可以有两种安装选项,一个是用户维度的,另一个是项目维度的。安装后的效果如图(在控制台我习惯展示3个窗口,安装位于最右边)
graphify installgraphify install --project
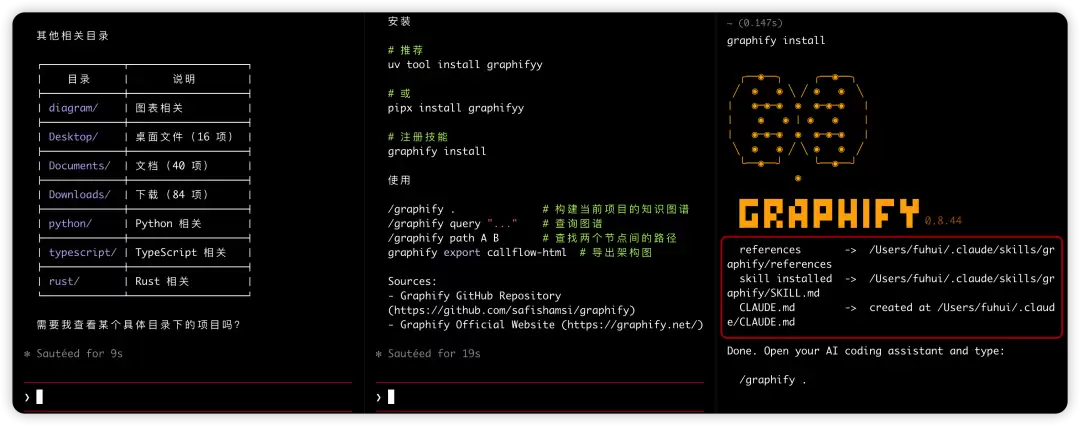 在 claude 命令行输入 /graphify 就可以正常触发,它既可以借助大模型来构建关系图,也可以直接基于语法树来构建。当务之急是找一个代码库来验证一下效果。当然 graphify 在自我介绍中这么说:
在 claude 命令行输入 /graphify 就可以正常触发,它既可以借助大模型来构建关系图,也可以直接基于语法树来构建。当务之急是找一个代码库来验证一下效果。当然 graphify 在自我介绍中这么说:Turn any folder of code, SQL schemas, R scripts, shell scripts, docs, papers, images, or videos into a queryable knowledge graph.
人家的定位可不仅仅是代码,只用来解决代码就太局限了。现在用代码来验证下效果当然可以。找一个 Go 语言的开源库算是比较靠谱的,阅读到这里的读者大多都和编程有点关系。
将 Go 的源码下载到本地,我们将分析目标局限在一个具体的包上。选择一个比较常用的 sync.map 的代码包分析,让大模型帮我们解释下,sync map 是如何来解决读写冲突问题的
git clone [email protected]:golang/go.git对于这类底层工具包,目录下的每个文件都代表了一种独立功能,文件和文件之间的关系非常简单,所以,我们通过 graphify 是想更加聚焦单个文件内部,我们要对这个目录构建知识图谱,但我们只想分析其中的 map.go 文件
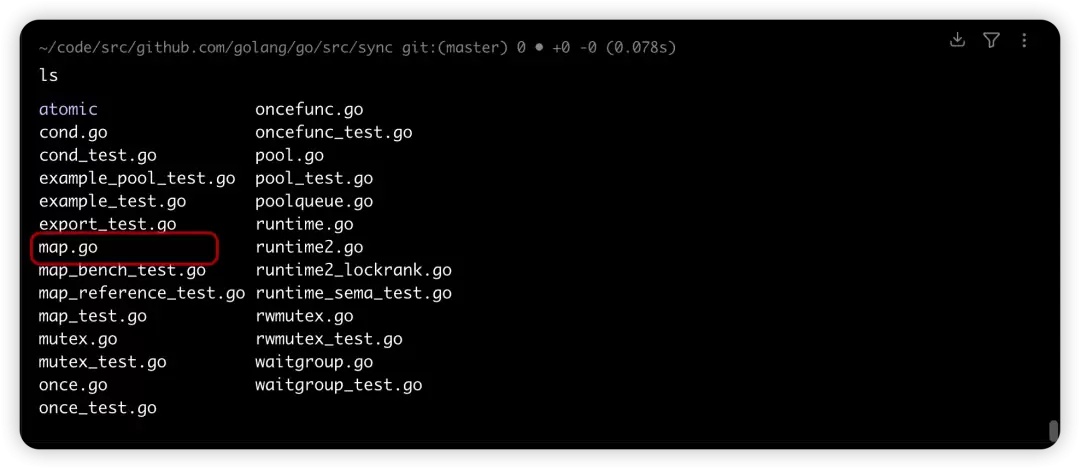
在目录下启动 claude,然后在命令行触发 graphify,系统开始执行,模型在不断地推理、执行、反思、再执行、经过了多次的问题修复,最终输出了:Graph: 658 nodes, 1369 edges, 38 communities 的效果图
No existing graph found. I will build the knowledge graph from the current directory

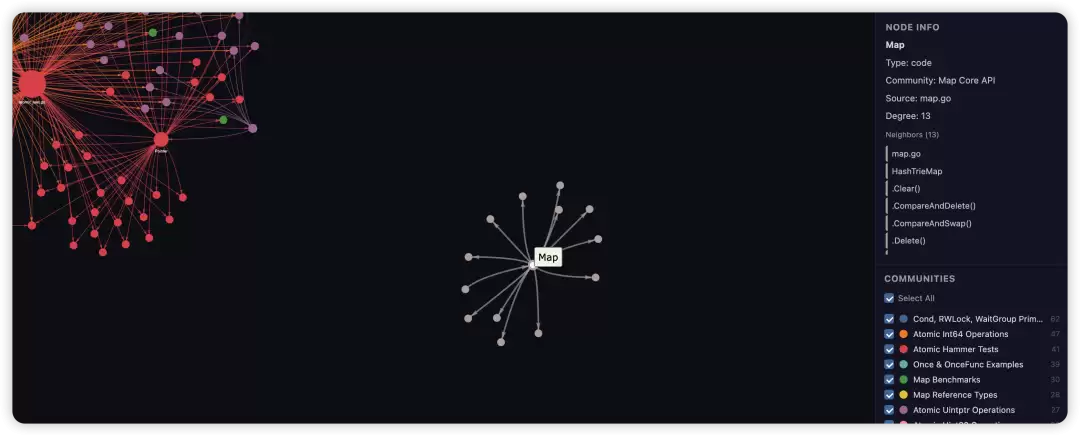
图谱底层生成采用的是社区检测算法,很明显,sync.map 的社区比较独立,和它相关的节点就是几个对应的函数,这个包确实不太适合来做分析。这个图中其实还有一个关键信息:置信度。
图的每条边上都有一个自信度的标记,Graphify 在提取实体和关系时使用三种置信度标记,分别是EXTRACTED (高置信度)、INFERRED (中等置信度) 、AMBIGUOUS (低置信度) ,这样的等级划分其实是可以参考的。
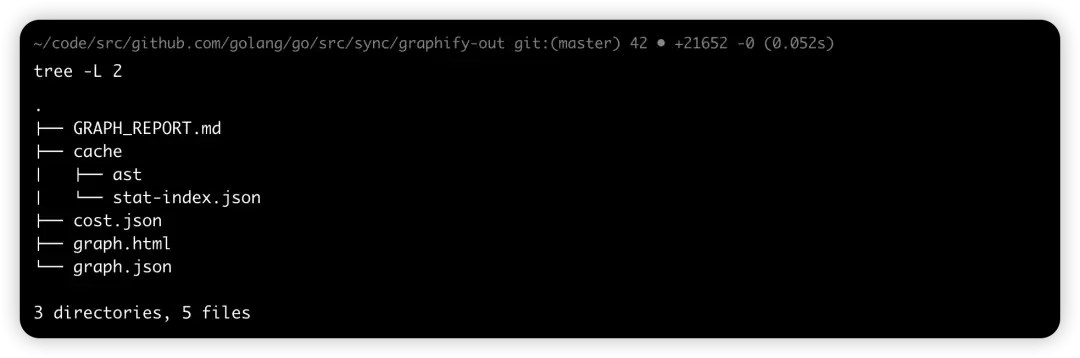
运行之后当前目录下生成了 graphify-out 文件夹,这几个文件。你可以打开 graph.html 查看可视化图谱(如上图),或根据 GRAPH_REPORT.md 中的建议问题探索代码库结构。
使用基础的 query 命令查询 map,对比命令行直接执行和在大模型中执行的效果。根据左侧命令的输出,程序使用广度优先搜索 (Breadth-First Search) 进行遍历。右侧是大模型的结果,直接输出了大模型处理后的结果。
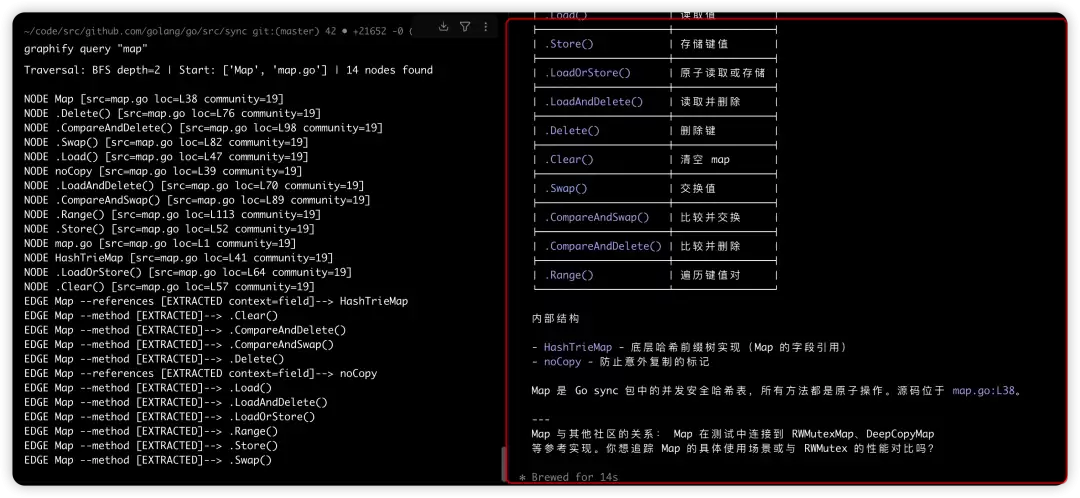
然后我对比一个贴近工作语义的问题,直接在大模型中输入:sync.map是如何解决并发读写问题的 vs /graphify sync.map 是如何解决并发读写问题的。后者的数据结果主要基于 /graphify 召回的节点进行分析。
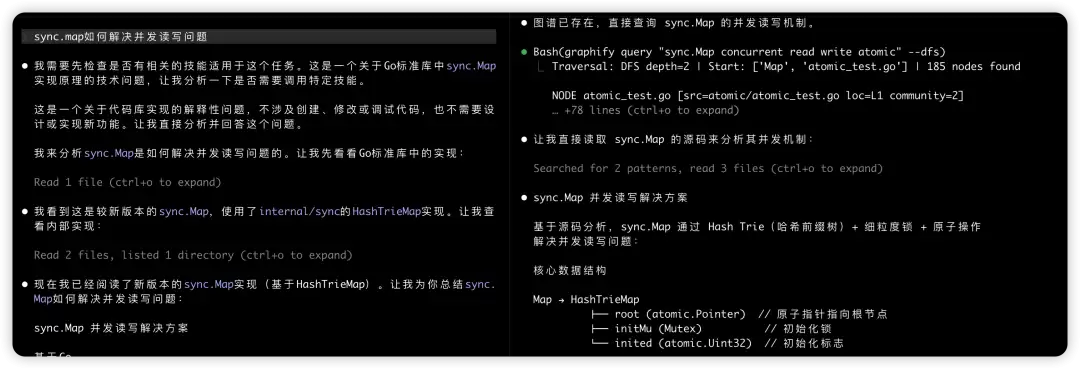
我们发现,graphify 在这个场景解决的是召回率的问题,结合生成的图谱,可以快速召回相关的数据。相比于 RAG 在构建知识库是文本固定切块,块与块之间保留一部分内部重合的模式,graphify 数据的召回内容相关性更好。
登录查看剩余 70% 内容
相关资讯
-
- 今年最糟的 AI 广告出现了:比审美降级更可怕的是“不做人”
- 2026-07-03
-
- 谷歌向苹果三星开火:深夜甩出四款AI手机 一键召唤Gemini 安卓全面AI化
- 2026-07-03
-
- Mamba再次挑战霸主Transformer:首个通用Mamba开源大模型一鸣惊人
- 2026-07-03
-
- 最强AI程序员砸饭碗:84秒跑通代码 像人一样思考 团队仅5人
- 2026-07-03
-
-
- 2B多模态新SOTA:华科、华南理工发布Mini-Monkey:专治切分增大分辨率后遗症
- 2026-07-03