ECCV 2026 连中三篇:群核科技联合NVIDIA、Adobe推出仿真器SPEAR
作者:互联网 时间: 2026-07-03 09:23:52
一个新的产业共识正在形成:物理 AI 的竞争,正在从算法层转向基础设施层。为什么基础设施突然变得如此关键?因为物理 AI 的学习方式与语言模型有着根本不同。大语言模型可以从互联网获取海量文本——那是人类千年文明的数字化沉淀。但机器人面对的是一个几乎不存在现成数据池的物理世界。
之前有份报告显示,全球高质量真实物理交互数据总量仅约 50 万小时,而要实现具身 AI 模型能力的突破,需要千万小时起步的数据量级。仿真训练,正在从“研发辅助工具”升级为 Physical AI 时代的核心基础设施。
就在这个节骨眼上,群核科技在 ECCV 2026 上连续入选三篇论文,实际上覆盖了具身智能、空间智能、世界模型等领域最关键的三大问题。从真实感仿真器的性能瓶颈突破,到全球尺度的交互式空间智能评测,再到强化学习中的数据自进化——三篇工作串起来,恰好勾勒出“仿真-数据-评测”一套完整的 Physical AI 基础设施雏形。
这不仅是学术层面的三连击,更是一份来自产业界的清晰信号:Physical AI 的竞争,正在从论文和模型,走向真正的"基建"之争。接下来,我们就逐一拆解这三篇论文,看群核科技究竟在哪三个关键问题上给出了答案。
SPEAR——真实感具身智能仿真器
论文背景
机器人去哪训练?是学术界和工业界一直探讨的难题。现实世界中,让机器人真机训练成本高、风险大、迭代慢。仿真训练是必经之路,但现有的仿真器总让人有种“隔靴搔痒”的感觉——要么画质不够真实,要么接口不够灵活,要么渲染速度贼慢。群核科技这次联合 Adobe 等机构共同推出了SPEAR:一个基于虚幻引擎(Unreal Engine,UE)的真实感具身智能仿真器。
SPEAR 代码地址:
https://github.com/spear-sim/spear

图. SPEAR 是一个 Python 库,能够通过模块化插件架构连接并以编程方式控制任何虚幻引擎应用程序
技术介绍
SPEAR:一款用于真实感具身智能研究的仿真器。SPEAR 的核心是一个 Python 库,通过模块化插件架构,能够连接并以编程方式控制任何虚幻引擎应用程序。SPEAR 的编程模型向 Python 开放了 14,485 个独特的 UE 函数(比现有的基于 UE 的仿真器高出一个数量级),并实现了每秒超过 1 亿像素(100 megapixels)的真实感渲染速度(比现有的 UE 插件快一个数量级)。
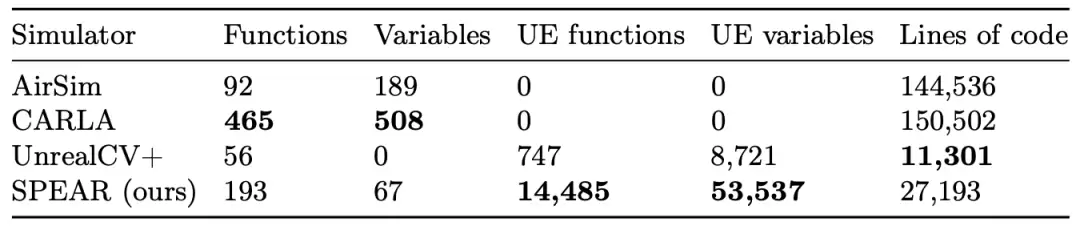
表. 各种 UE 仿真器可编程功能的比较

图. SPEAR 编程模型
更值得一提的是 SPEAR 的异步编程模型。SPEAR 为每个函数都提供了异步变体,避免与 UE 进行同步,同时实现了无需数据拷贝即可在 UE 函数与 Python 代码之间传递 NumPy 数组的机制。这使得 SPEAR 能够以原生帧率执行用户 Python 代码。

图. 展示了如何利用编程模型中的异步操作来彻底避免阻塞 UE 游戏线程,从而使 UE 应用程序能够以原生帧率执行用户的 Python 代码
在编程模型层面,SPEAR 的 UE 工作图被指定为事务(transactions)。用户通过定义 begin_frame 和 end_frame 上下文来指定一个事务。在每个上下文中,用户只需通过编写 Python 代码来实现 UE 任务图。
此外,SPEAR 还集成了进程间共享内存机制,进一步优化了系统的效率。通过使用共享内存,可以将渲染后的图像直接从 GPU 传输到用户的 NumPy 数组中,而无需进行额外的数据复制。
实验结果
SPEAR 的实验结果可以用“降维打击”来形容。
在可编程功能数量上,SPEAR 支持了超过 14,000 个 UE 函数和变量,而现有 UE 仿真器(CARLA、AirSim、UnrealCV 等)仅提供数百个。与此同时,SPEAR 的代码量却维持在极其精简的水平—— Python和 C 代码行数均远低于基线系统。在渲染性能上,SPEAR 将 真实感图像转为仿真可用的 Numpy 数组的速度达到56帧/秒——比现有 UE 插件快一个数量级。具体对比来看,SPEAR比 UnrealCV 快15倍,比 AirSim 快12倍,与 CARLA 端到端性能相当,同时支持更高质量的真实感渲染。在应用示范方面,SPEAR 展现了惊人的灵活性:可以控制城市尺度环境中 6 种不同动作空间的具身智能体(人类、汽车、飞行机器人、四足机器人等),操纵 UE 的程序化内容生成系统,渲染高精度人脸的多视角图像,以及与 MuJoCo 物理引擎进行交互式协同仿真。由上可知,SPEAR 性能强大,有望成为计算机视觉、机器人学和具身智能领域的基础性数据引擎。
除了硬核技术方面,这篇论文还非常值得一提的是,除了群核科技的参与之外,作者阵容相当强大!都是来自产业界的长期深耕于仿真、3D视觉方向的大佬,除了论文的重要作者 Adobe 高级研究科学家 Mike Roberts,还有:
German Ros:英伟达仿真生态系统开发总监。Stefan Leutenegger:苏黎世联邦理工学院副教授,代表工作有:BRISK、ElasticFusion等。Kalyan Sunkavalli:Adobe 研究院的首席科学家,代表工作有:LRM、Point-NeRF等。Vladlen Koltun:Apple 的杰出科学家,谷歌学术引用量突破10w !在 2017 年 11 月推出自动驾驶测试基准 CARLA,已成为自动驾驶领域广泛使用的基准测试平台。所以 SPEAR 会更在意解决仿真里的那些实用性问题。
WalkerBench——基于真实街景的交互式空间智能评测基准
论文背景
如何评测空间智能,正在成为 Physical AI 领域一个日益紧迫的问题。目前主流的视觉语言模型在二维图像理解上的能力持续突破,但在三维空间推理上的表现却始终难以量化——因为行业缺少一把能“测准”的尺子。
现有的空间智能评测基准有个通病——它们让 AI 当“观众”,也就是采用“旁观者视角”(Spectator View),给一张静态图片或一段视频,让模型“猜”空间关系。但真正的空间智能,使具身智能体能够与物理世界进行主动交互——通过移动来消除几何歧义,通过多视角观察来建立空间认知。这一测,就暴露了 VLM 的真实短板。
WalkerBench 代码地址:
https://github.com/lalayang123456-ctrl/WalkerBench
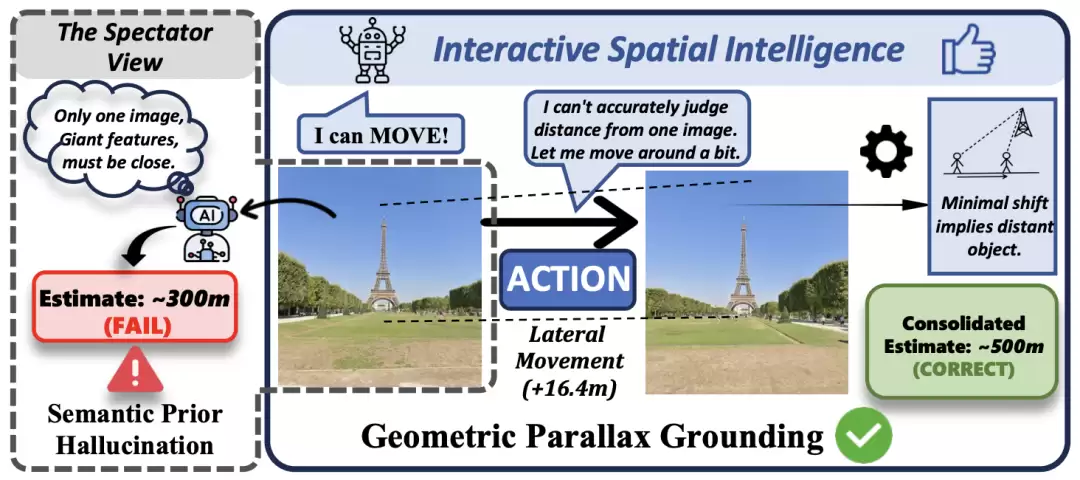
图. 静态感知与交互式空间智能
技术介绍
针对这一问题,群核科技联合浙江大学等推出了 WalkerBench:首个建立在真实街景和地图数据之上的全球尺度交互式空间智能评测基准,覆盖全球 160 多座城市,包含两大类层次化空间任务。
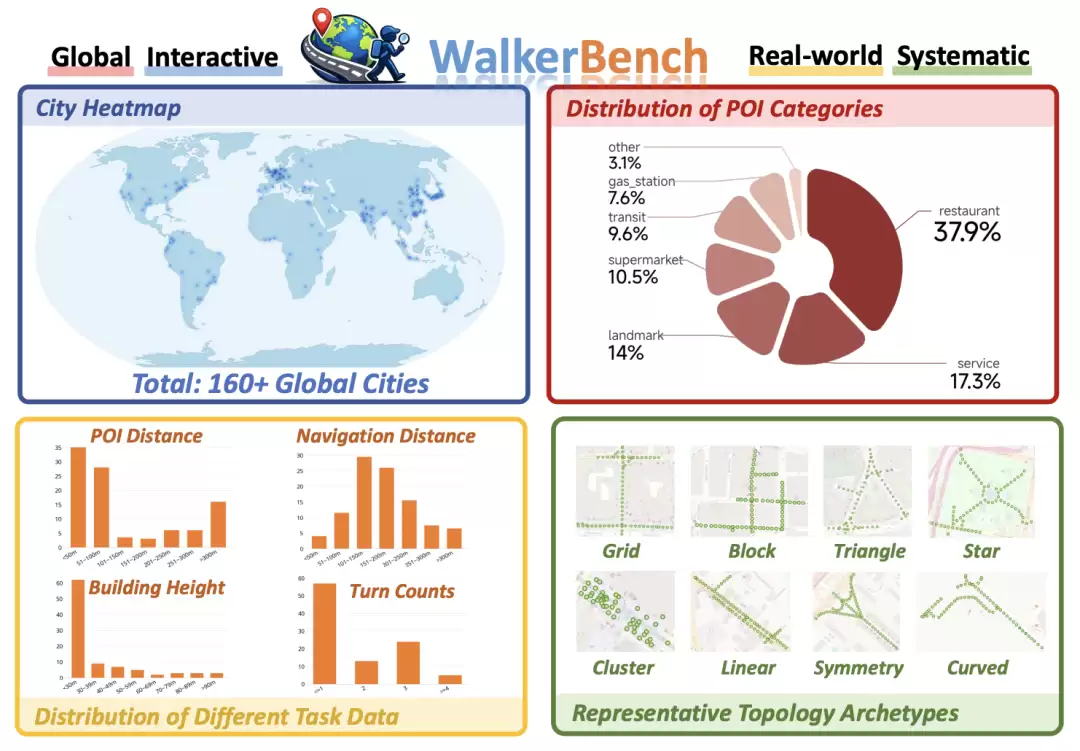
图. WalkerBench 概览
WalkerBench 两大任务:
主动感知(Active Perception) :智能体必须通过主动移动来解析几何歧义,完成距离估计、建筑高度估计、相对方位估计等度量任务。空间导航(Spatial Navigation) :智能体需在 8 种城市拓扑结构(Grid、Block、Star、Curved等)中完成长程导航,细分为 Geometric Navigation(剥离街名的纯结构导航)和 Visual Semantic Navigation(基于地标描述的多模态导航)。数据构建上,WalkerBench 采用了一套全自动数据引擎——通过各向同性的 BFS 扩展、虚拟链接补全、贪婪最远点采样等机制,从 2,408 个原始候选中蒸馏出 1,000 个高质量精心设计的任务。更重要的是,WalkerBench 剥离了街名、大量采样非英语城市(如达卡、罗安达、卡拉奇)来抑制世界知识记忆,确保评测的是实时的视觉推理能力而非记忆的地理知识。
针对 VLM 线性上下文与 3D 拓扑任务之间的根本性不匹配,WalkerBench 配套提出了 Spatial-IDE 框架,它通过两种机制运作:
State Externalization(状态外化) :将隐式观测转化为显式拓扑记忆(ETM) ——一个动态图结构,记录节点的坐标、朝向、遍历历史和语义注释,并以固定 token 预算序列化,从根本上杜绝了“走着走着就忘了”的问题。Cognitive Decoupling(认知解耦) :将视觉理解拆解为目标导向感知(Goal-Directed Perception)——只回答推理引擎提出的具体问题,如“药店招牌是否可见,方位多少?”)和空间推理引擎(Spatial Reasoning Engine),让 VLM 专注于纯高层决策,不再被冗长的历史上下文压垮。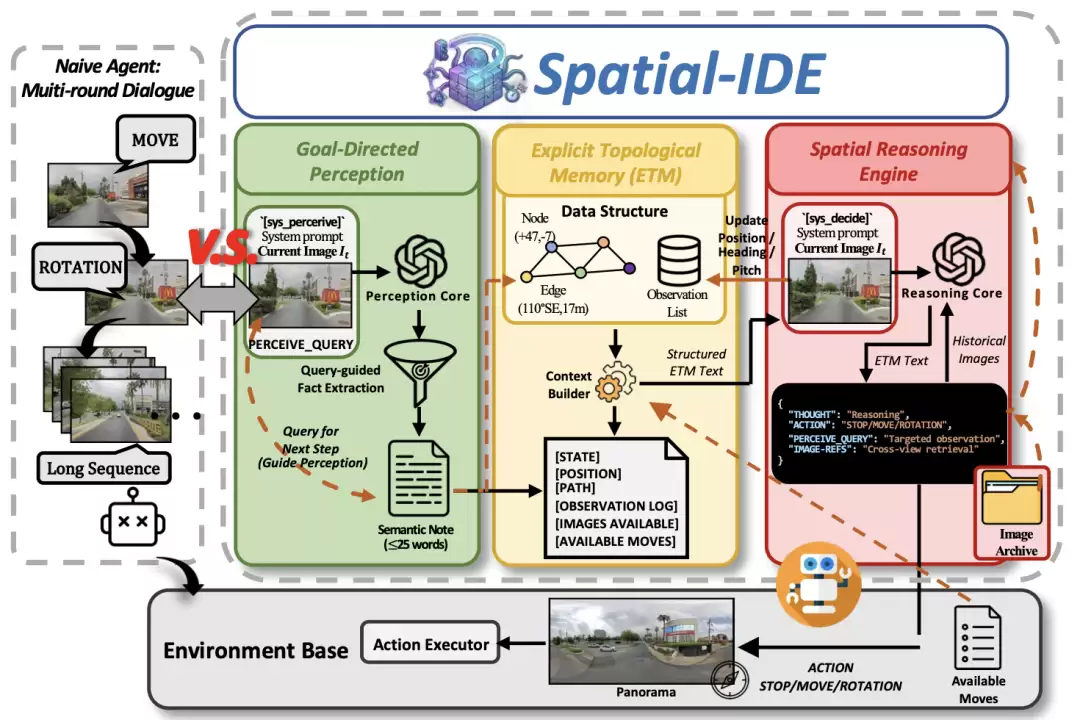
图. Spatial-IDE 框架
实验结果
WalkerBench 的评测结果可以用三个“震撼”来概括。
第一组震撼:人类 vs 模型。人类得分 69.43%,而最好的 VLM Agents(Claude-Opus-4.6)仅达到24.49%。这一巨大差距表明,当前 VLM 在交互式空间智能任务上远未饱和。
第二组震撼:Spatial-IDE 让模型性能全面显著提升。Spatial-IDE 让所有 9 个被测的 VLM Agents 模型取得了一致且巨大的提升 —— 平均提升 104.97 % 。Claude-Opus-4.6从 24.49% 跃升至 43.17%( 76.28%),GLM-4.6V 从 13.31% 跃升至 31.77%( 138.69%)。值得注意的是,GPT-5-chat-latest 原始排名垫底,但在 Spatial-IDE 帮助下,性能提升 119.98%,说明其缺陷主要在于上下文管理失效而非感知能力本身。
第三组震撼:零样本迁移到真实机器人。Spatial-IDE 被直接部署到宇树 G1 人形机器人上,在真实城市环境中完成了千米级多街区自主导航——仅靠自然语言指令和机载 RGB 摄像头,无需任何环境特定微调。这证明 WalkerBench 中学到的空间推理能力可以直接迁移到物理世界。
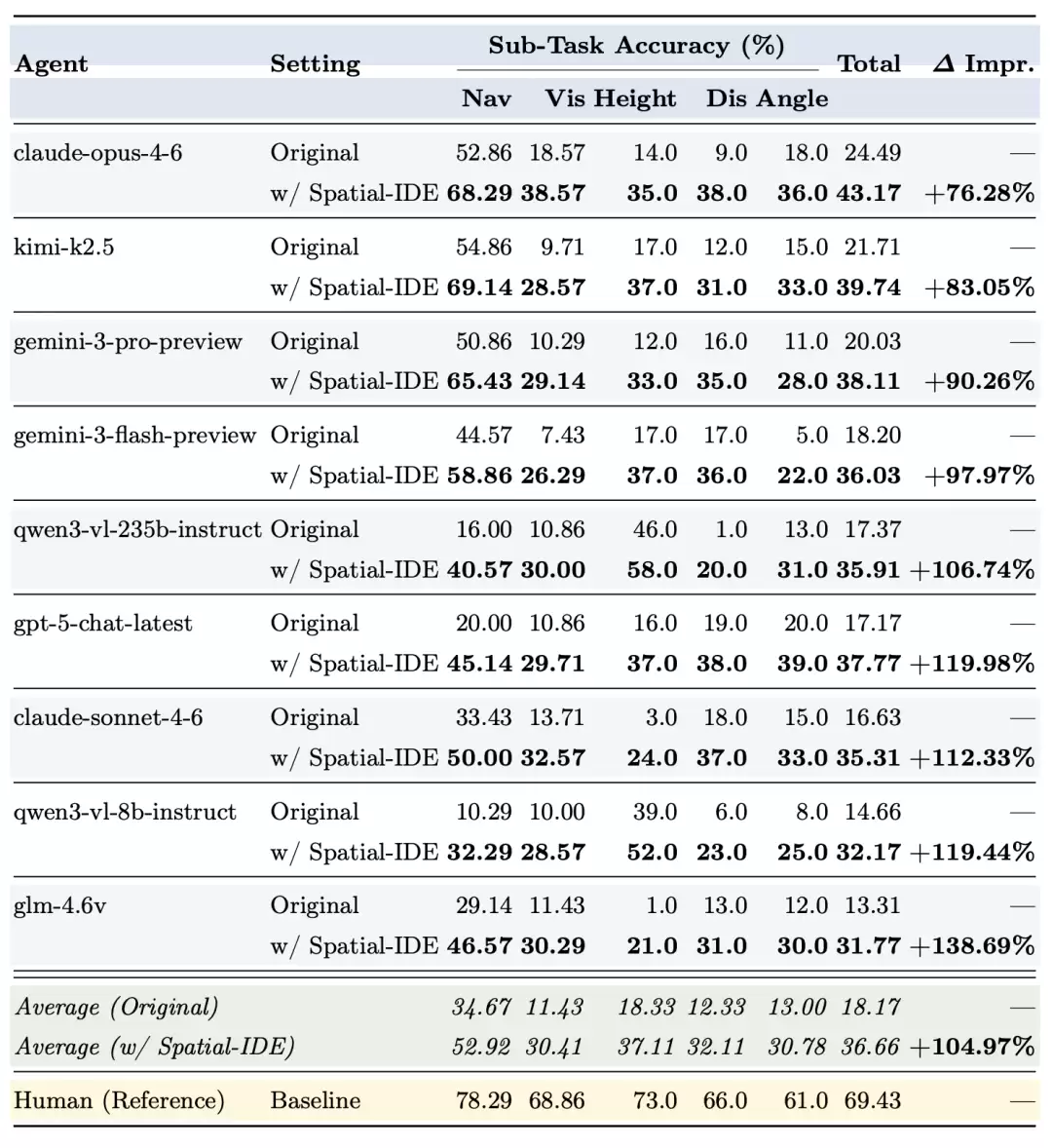
表. 本文详细分析了使用和不使用 Spatial-IDE 的视觉语言智能体在各个子任务和整体上的性能,以及相对于原始设置的总分提升。子任务得分和总分均以准确率(%)表示。人类(参考)作为上限基线
消融实验进一步表明,ETM 和 GDP 两大组件具有显著的协同效应:单独加 ETM 提升 9.66 点,单独加 GDP 提升 11.97 点,而两者结合提升高达 18.49 点,这说明“记住什么”和“看什么”这两个子问题被解耦后,VLM 才能真正发挥其推理潜力。
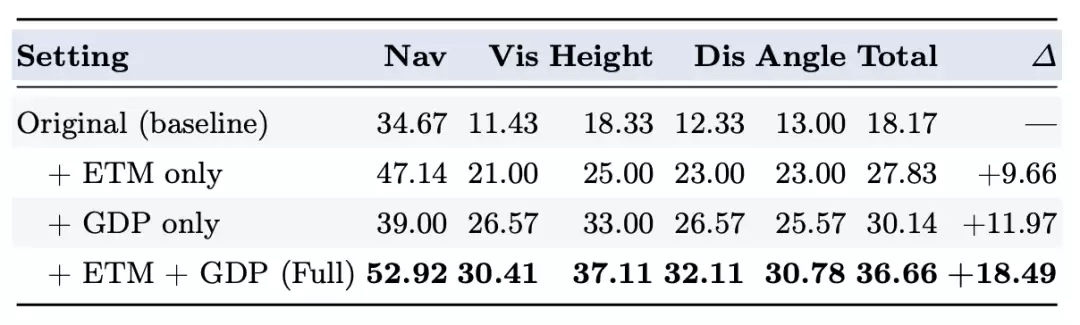
表. 针对 Spatial-IDE 两个核心组件的消融实验。所有数值均为九个智能体的平均值。子任务得分及总分均以准确率(%)表示。∆ 表示相对于原始基线的绝对提升
Syn-GRPO——自进化数据合成与强化学习框架
论文背景
DeepSeek-R1 的横空出世让 GRPO(Group Relative Policy Optimization)成为后训练阶段的核心算法之一。然而,有一个棘手的问题:GRPO 训练中,多模态大语言模型(MLLM)的熵和多样性呈现急剧下降趋势,即所谓的“熵崩溃”和“多样性崩溃”。本质上,这是因为现有视觉感知数据集的样本格式过于单一,无法激发 MLLM 的多样化响应,从而严重限制了 RL 的探索空间。现有方法如 CLIP-Higher、Clip-Cov 等都试图从 GRPO 算法本身入手来缓解这一问题,但始终无法从根本上突破低质量数据的天花板。
Syn-GRPO 代码地址:
https://github.com/hqhQAQ/Syn-GRPO
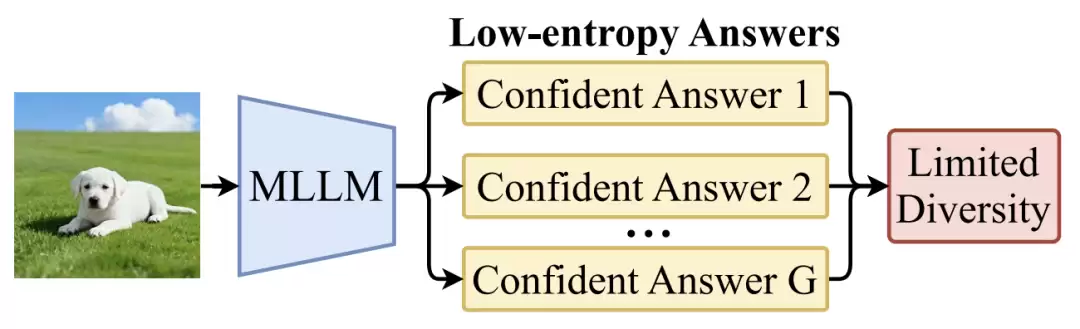
图. 在 GRPO 训练中,MLLM 生成的答案缺乏多样性且熵值较低,从而限制了强化学习(RL)的探索空间
技术介绍
群核科技联合浙江大学提出的 Syn-GRPO(Synthesis-GRPO)给出了一个全新的解决思路:为什么不直接在训练过程中动态合成更高质量的数据呢?
Syn-GRPO 由两大组件构成:
1)数据服务器(Data Server)
这是业界首个针对图像模态突破数据局限的在线合成系统。数据服务器基于原始图像和新图像描述,通过outpainting 模型生成全新图像。其两大核心特征是:
前景一致性(Foreground Consistency) :先用前景分割模型去除无关背景,再用 outpainting 模型生成新背景。这使得视觉感知任务的标签(如边界框)在新图像中保持完全正确,同时通过保留前景来缓解新老数据分布差异过大的问题。解耦设计(Decoupled Design) :数据服务器与 GRPO 工作流完全解耦,通过统一 API 通信。这使得数据生成和 GRPO 训练可以异步执行,几乎不增加额外训练时间。2)GRPO 工作流
GRPO 工作流在原始 GRPO 基础上引入了三个关键改进:
新图像描述(New Image Description) :MLLM在 输出推理过程和最终答案之外,还需预测一个用于生成新图像的文本描述。多样性奖励(Diversity Reward) :MLLM 同时预测“预测多样性”,通过比较预测多样性与实际 rollout 多样性(准确率奖励的方差)来计算奖励,从而监督 MLLM 学会为那些能激发多样响应的样本生成更好的图像描述。为应对训练过程中多样性整体漂移的问题,还引入了多样性平滑策略——使用指数移动平均来校准每个 batch 的多样性。描述选择(Description Selection) :从 G 个响应中选择多样性奖励最高的图像描述发送给数据服务器。最终的奖励函数为:准确率奖励 格式奖励 多样性奖励。模型在最大化这一综合奖励的过程中,既能提升任务精度,又能学会“如何描述一张能让模型学到更多东西的图像”。
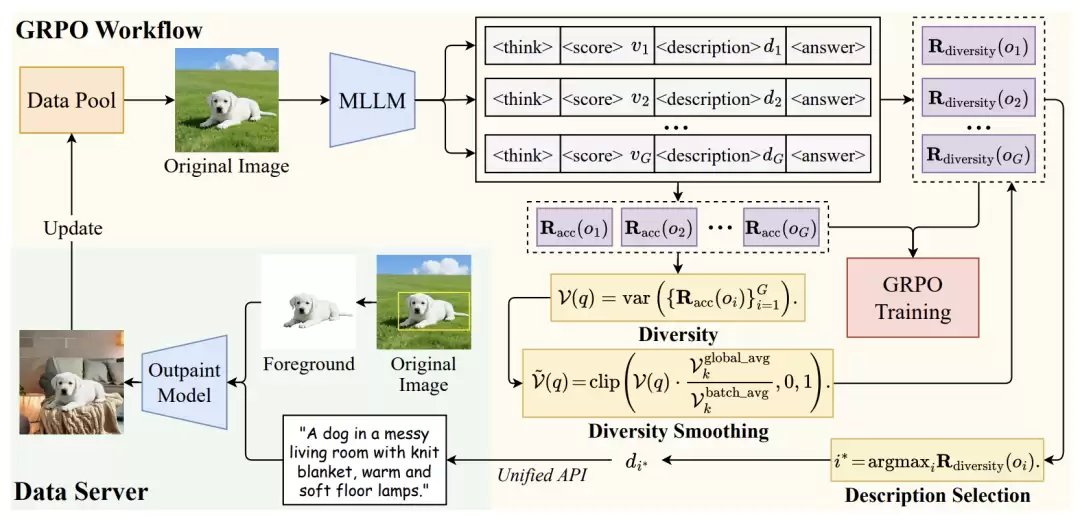
图. Syn-GRPO 框架
实验结果
Syn-GRPO 在 REC(Referring Expression Comprehension)、OVD(Open-Vocabulary Object Detection)和 ISR(Indoor Scene Refinement) 三项视觉感知任务上均取得了显著超越现有方法的性能。
在 REC 任务上,Qwen2.5-VL-3B (基线模型) Syn-GRPO 在 LISA-Grounding 数据集上达到 68.28 % ,远超 VLM-R1 的 63.14 % 和 GRPO 的 62.24 %;在 RefCOCO 数据集上达到 92.15 %,同样全面领先。
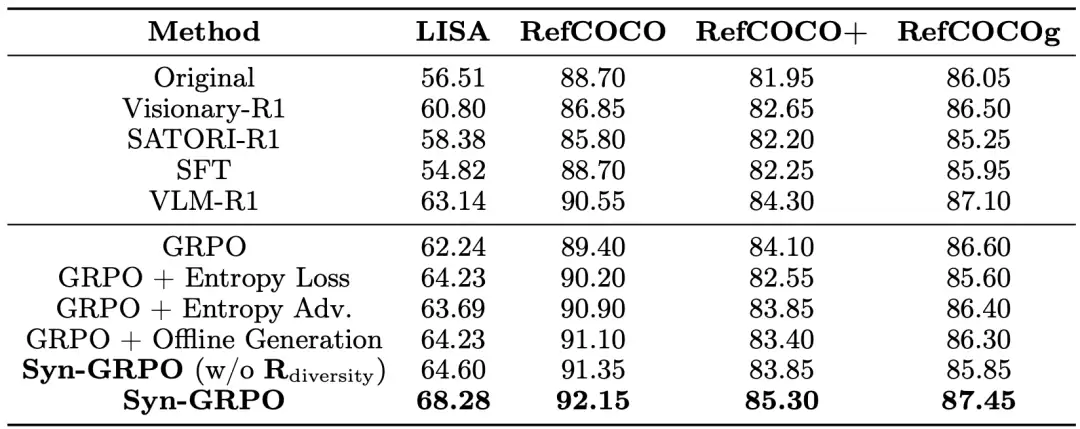
表. Qwen2.5-VL-3B 在 REC 任务上的实验结果
在 OVD 任务上,Syn-GRPO 的 mAP 达到 23.74 %,GP 达到 71.42 %,GR 达到 46.44 %,全面超越 GRPO 和 VLM-R1。
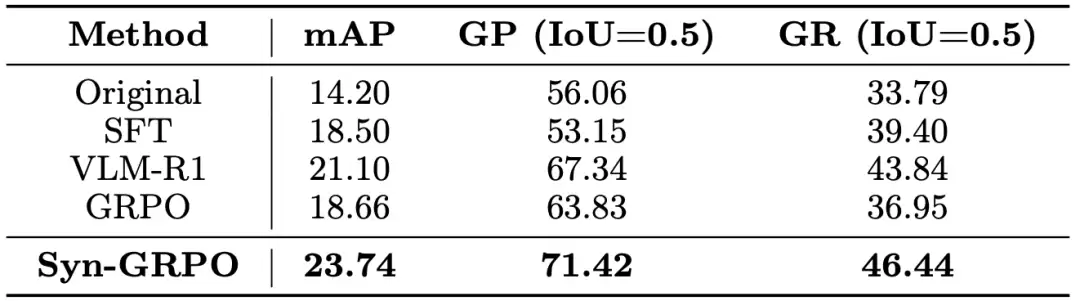
表. OVD 任务上的实验结果
更值得关注的是两组揭示性现象:
数据规模 Scaling Law:随着训练数据从 400 增加到 2,000 样本,Syn-GRPO 的性能呈现持续稳定上升趋势,预示着在更大规模 RL 训练中具有长期可扩展性。生成数据复杂度递增:随着训练迭代推进,生成的图像呈现出越来越复杂的趋势——这意味着 Syn-GRPO 是一个真正的“自进化”系统,能够自适应地生成越来越有挑战性的样本,而不是像传统方法那样越训越“死”。此外,解耦设计使异步 Syn-GRPO 的训练时间仅比原始 GRPO 多约 5%,而同步设计则会使训练时间翻倍。多样性平滑策略也显著提升了训练的稳定性和最终精度。
在 REC、OVD 和 ISR 这三大项视觉感知任务上的实验结果表明,Syn-GRPO 显著提升了数据质量,且性能大幅优于现有的强化学习方法。
总结
回头看群核科技这三篇 ECCV 2026 论文:
SPEAR 解决了“在哪训练”的问题——提供了一套高速、高真实感、高灵活性的仿真基础设施;WalkerBench 解决了“怎么评测”的问题——提供了一个全球尺度、真实场景、交互式的空间智能评测基准;Syn-GRPO 解决了“高质量数据从哪来”的问题——提供了一套能在训练中自我进化的数据合成框架。从仿真平台到评测基准,再到数据进化,群核科技此次 ECCV 2026 的三篇论文,已经初步搭建起物理AI训练所需的关键能力链条,形成了一个动态进化的数据飞轮。
相比单点算法创新,更值得关注的是,这些工作共同指向了一套完整的 Embodied AI 基础设施。当Physical AI 的竞争正从算法层加速转向基础设施层时,谁先建成这套“路、桥、港”,谁就将在机器人与具身智能的下一阶段竞争中占据先机。而这,或许才是群核科技这三篇 ECCV 2026 论文背后真正的战略意义所在。
整理不易,请点赞和在看
 图片
图片
相关资讯
-
- 《今古群侠传》最强钓鱼竿获取攻略-玲珑钓竿与缠龙竿获得方法
- 2026-07-03
-
- 《今古群侠传》泾水城任务指南-泾水城全任务完成方法详解
- 2026-07-03
-
- 三国群英传策定九州指的是什么游戏 三国群英传策定九州游戏类型分享
- 2026-07-03
-
- 今古群侠传连星弓获取攻略-蛇岛宝箱详解
- 2026-07-03
-
- 《今古群侠传》武学易筋经获得攻略-扫地神僧挑战技巧详解
- 2026-07-03
-
- 暗黑破坏神4S14蠕虫点位汇总
- 2026-07-03